
Actual-time voice merchandise stay or die by latency. Whether or not it’s a voice assistant, an in-game announcer, or a stay translation instrument, how rapidly speech begins enjoying defines your entire person expertise. For builders, milliseconds matter. The sooner a mannequin begins producing audio, the extra “alive” the interplay feels.
On this benchmark, we evaluated the quickest streaming TTS fashions from Async Voice API, ElevenLabs, and Cartesia to raised perceive the steadiness between latency and perceived voice high quality. Particularly, we measured and in contrast:
• Mannequin-level latency – time spent on GPU inference solely, excluding networking and utility overhead.
• Finish-to-end latency – time from request initiation to first audio byte (TTFB) obtained by the shopper.
• Subjective audio high quality – assessed utilizing pairwise Elo rankings throughout a number of voice samples.
All benchmarks have been executed beneath an identical situations, repeated a number of instances for statistical confidence, and averaged throughout randomized immediate units to keep away from caching bias.
Methodology
To measure real-world streaming efficiency precisely, we used a two-layer benchmarking framework designed to separate uncooked mannequin pace from full end-to-end latency. This enables us to isolate how a lot of the delay comes from mannequin inference itself versus infrastructure or community overhead, a key distinction for builders optimizing real-time methods.
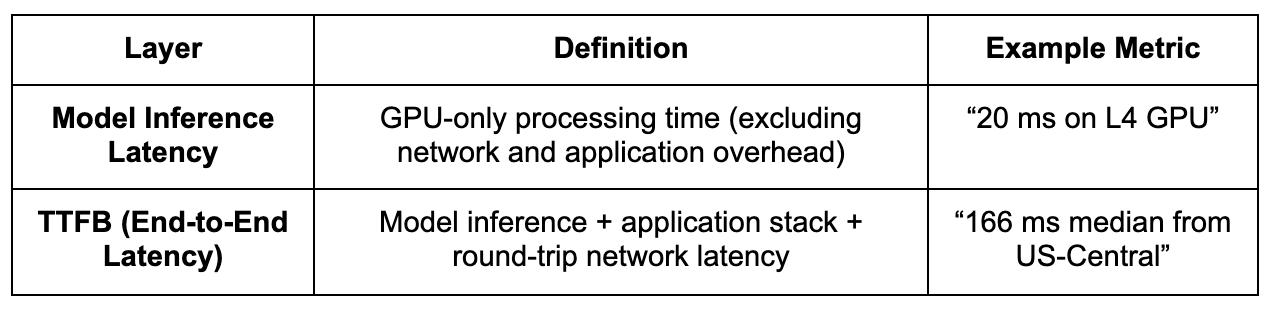
By measuring each layers, we seize an entire view of system efficiency, from infrastructure effectivity to user-perceived responsiveness. This technique is especially related for low-latency streaming use instances corresponding to AI voice assistants, real-time dubbing, stay narration, and transcription playback, the place even a 100 ms delay could make interactions really feel sluggish or desynchronized.
Take a look at atmosphere
We saved each benchmark run beneath the identical shopper and community setup to make the comparability truthful and repeatable. That manner, any variations you see come from the fashions themselves, not from community noise or {hardware} quirks.

All evaluations have been carried out utilizing streaming API endpoints, the place accessible, to measure first-byte latency and steady audio throughput.
To get rid of warm-up bias, every mannequin underwent three warm-up runs, adopted by 20 measured iterations, with metrics aggregated utilizing each median and p95 (ninety fifth percentile) values.
Mannequin inference latency
Earlier than accounting for API or community overhead, mannequin inference latency displays the uncooked computational pace of a text-to-speech mannequin operating on GPU {hardware}. This metric isolates how effectively the mannequin itself converts textual content into audio frames, impartial of streaming protocols or shopper connectivity.
Decrease inference latency usually signifies:
• Higher architectural optimization
• Quicker response instances on equal GPU {hardware}
• Diminished serving prices when deployed at scale
The next desk summarizes pure inference efficiency for every supplier’s flagship streaming mannequin.

Be aware: AsyncFlow’s structure is optimized for L4 GPUs, reaching close to floor-level inference instances of ~20 ms. The dearth of disclosed GPU information from ElevenLabs and Cartesia suggests their outcomes might depend on higher-tier GPUs, which makes AsyncFlow’s efficiency-to-cost ratio stand out much more.
Streaming latency benchmark (end-to-end)
Whereas uncooked inference pace reveals how rapidly a mannequin can course of textual content on a GPU, end-to-end streaming latency determines how responsive it feels in an actual utility. To seize each startup delay and whole completion time, we measured Time to First Byte (TTFB) and whole audio period throughout a number of runs.
Every take a look at consisted of:
• 20 benchmark iterations per mannequin (after three warm-up runs to normalize cold-start results)
• Constant shopper situations from us-central1
• HTTPS streaming requests utilizing an identical textual content prompts and audio configurations
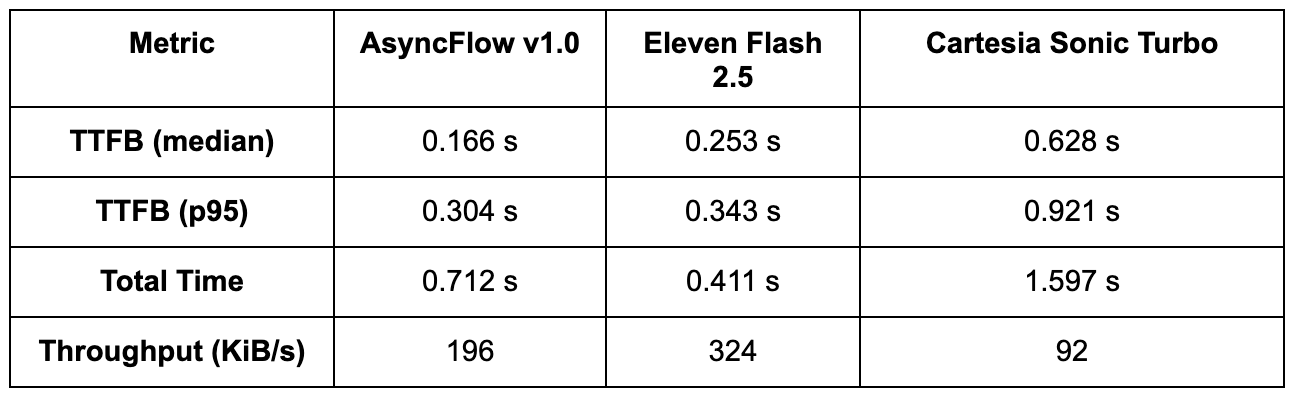
Be aware: p95 (ninety fifth percentile) signifies that 95% of requests accomplished sooner than this time, offering a sensible measure of latency consistency beneath load.
Interpretation:
• AsyncFlow delivers audio earliest; its sub-200 ms median TTFB makes it supreme for interactive or conversational functions the place customers count on speech to start out virtually immediately.
• Eleven Flash streams at a barely greater latency however achieves sooner whole completion, suggesting a extra aggressive buffering or chunking technique.
• Cartesia Sonic Turbo trails considerably behind each, with over 3× slower TTFB and decrease throughput, which can restrict its suitability for real-time use instances.
These measurements embrace mannequin, API stack, and community latency, offering a true-to-life reflection of client-perceived streaming efficiency.
Benchmarking code instance
To maintain our measurements clear and reproducible, we used a easy Python benchmarking script that data each time-to-first-byte (TTFB) and whole response period for every supplier’s streaming API. The script sends an identical textual content prompts, timestamps key occasions (request begin, first audio chunk, and remaining byte), and aggregates the outcomes throughout a number of runs to calculate median and p95 latencies.
👉 The latency benchmarking code right here.
You’ll be able to simply adapt this script to check your personal fashions or infrastructure by adjusting the endpoint URLs, payload format, or concurrency parameters.
Subjective high quality analysis
That is an inner analysis following the TTS Enviornment framework, focusing solely on three low-latency fashions. Within the public TTS Enviornment, fashions typically goal totally different use instances, which makes it troublesome to instantly examine the standard of low-latency fashions.
A panel of 20+ individuals evaluated ~500 pairwise comparisons, every time selecting the pattern that sounded extra pure, expressive, and freed from artifacts. The outcomes have been aggregated and normalized into Elo scores, which quantify relative desire energy slightly than absolute high quality.

Findings:
• Eleven Flash v2.5 achieved the very best Elo rating, demonstrating barely stronger prosody management and expressive readability, notably for emotional or punctuation-heavy prompts.
• AsyncFlow ranked an in depth second, with its efficiency remaining remarkably constant and minimal robotic artifacts even beneath aggressive streaming latency. Contemplating its ~34% sooner TTFB and decrease serving value, AsyncFlow gives a wonderful quality-to-latency ratio.
• Cartesia Sonic Turbo trailed behind, with decrease listener desire primarily resulting from artificial artifacts and intonation drift at greater streaming charges.
Mixed insights
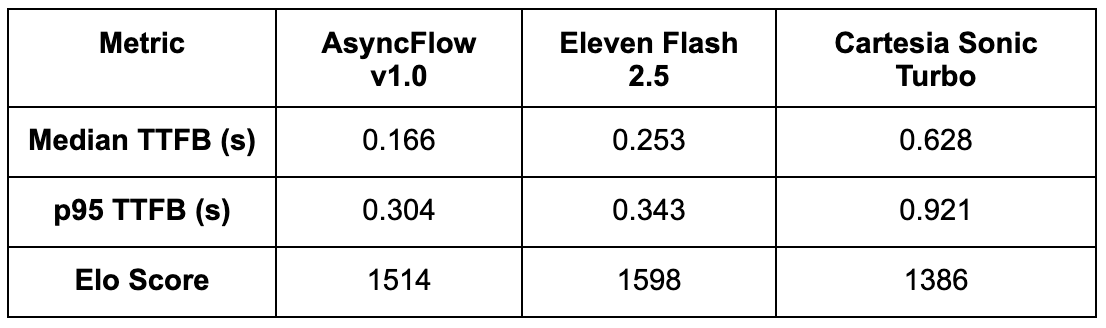
Key Takeaways:
• AsyncFlow leads decisively in time-to-first-byte (TTFB), outperforming ElevenLabs by ~34% and Cartesia by ~74% on median latency. Customers hear the primary sound sooner, which is essential for real-time, conversational experiences.
• Even on the ninety fifth percentile (p95), AsyncFlow stays 11% sooner than ElevenLabs and 67% sooner than Cartesia, displaying stability and predictability throughout requests, a vital property for high-concurrency functions.
• ElevenLabs retains a slight edge in subjective naturalness, notably in expressive speech supply. Nevertheless, AsyncFlow’s shut Elo rating and considerably decrease latency make it a extremely compelling different.
• AsyncFlow’s structure delivers industry-leading latency and superior value effectivity, particularly on mid-tier GPUs just like the L4. For builders constructing real-time TTS pipelines, AsyncFlow gives one of the best latency-to-quality ratio among the many fashions examined.
Why sub-200 ms latency issues
In human dialog, even brief silences are noticeable. Research present that people start perceiving a “pause” at round 250–300 ms of silence. For streaming TTS methods, hitting under this threshold is vital: it permits speech to really feel fluid, instant, and conversational, slightly than delayed or robotic.
Attaining sub-200 ms Time-to-First-Byte (TTFB) allows quite a lot of real-time functions:
• Pure turn-taking in voice assistants: Customers count on on the spot responses throughout interactive dialogues. Latencies above 250 ms could make a voice assistant really feel sluggish or interruptive.
• Low-latency dubbing for stay streaming: For stay content material, each millisecond counts. Quicker TTS ensures that speech stays synchronized with video or occasion cues.
• Actual-time transcription playback: Streaming text-to-speech can flip textual content outputs into on the spot audible suggestions, enhancing accessibility and value for stay captioning or voice-based interfaces.
With a median TTFB of 166 ms, AsyncFlow comfortably sits under this perceptual threshold, delivering human-like responsiveness with out counting on costly, high-tier GPU {hardware}. This makes it notably appropriate for interactive, low-latency functions at scale.
Assets & reproducibility
• Latency benchmarking code
• Async Voice API Developer Docs
• Cartesia API Reference
• ElevenLabs Streaming API Docs
Conclusion
AsyncFlow demonstrates that low latency, stable high quality, and price effectivity can coexist in a single streaming TTS engine.
Whereas ElevenLabs stays a benchmark in audio naturalness, AsyncFlow’s architectural effectivity, GPU-level optimization, and sub-200 ms TTFB make it a compelling choice for builders constructing real-time, interactive voice methods.
For any system the place perceived responsiveness defines person expertise, Async Voice API at the moment leads the sphere.
Subsequent step
Wish to run these checks your self? Discover the Async Voice API documentation and check out the benchmark script with your personal inputs.