By Parth Jain, Rakesh Sukumar, Yingwu Zhao, Renzo Sanchez & Nathan Fisher
How we constructed a dwelling map of our distributed infrastructure to assist engineers perceive dependencies, troubleshoot quicker, and maintain Netflix working easily for our members across the world.
The Puzzle with a Thousand Items
Image this: It’s 3am, and an engineer will get paged. Considered one of our vital providers is exhibiting elevated error charges. Members making an attempt to observe their favourite movies and collection are seeing degraded experiences. The clock is ticking.

In a system with 1000’s of microservices supporting our leisure expertise for members worldwide, answering these questions rapidly can imply the distinction between a minor blip and a significant incident.
We stored listening to variations of this story from engineers throughout Netflix. The tooling hole was clear: we had loads of indicators, however no unified strategy to perceive how the whole lot related.
The Three Questions Each Engineer Asks
When troubleshooting distributed programs, engineers basically want to grasp relationships:
Which providers depend upon one another? Not simply theoretical dependencies from configuration recordsdata or structure diagrams, however precise runtime connections based mostly on actual visitors.
What’s the blast radius? When one thing breaks or must go down for upkeep, what else can be affected? Which groups must be notified?
The place’s the supply? Is my drawback brought on by an upstream situation, or am I the foundation trigger that’s cascading to others?
Conventional observability instruments present fragments of this image. Metrics present signs and efficiency traits. Logs present particular person service habits. Traces present single request flows by way of the system. However none of them present the entire map of how the whole lot connects — the steady-state topology of dependencies that kinds the spine of our distributed structure.
For an engineer at 3am, having to mentally sew collectively data from a number of instruments is gradual, error-prone, and anxious. We would have liked one thing higher: a unified view of service dependencies — a map exhibiting how the whole lot connects — with straightforward navigation to the detailed indicators when it is advisable to dig deeper.
Why This Issues Extra Than Ever
Netflix runs on 1000’s of microservices working collectively to ship leisure to our members. If you press play in your favourite collection, that single motion triggers a cascade of service-to-service calls — authentication, suggestions tailor-made to your tastes, video encoding choice, playback optimization, and extra.
This structure provides us great flexibility and permits lots of of engineering groups to innovate independently. However it additionally creates basic observability challenges.
And these challenges had been rising. New initiatives like our Reside programming and Adverts-supported plans require much more refined monitoring and quicker troubleshooting. Reside occasions can’t look forward to prolonged incident investigations. The dimensions and real-time nature of those programs demanded higher tooling.
We analyzed 1000’s of assist requests from our engineers over a four-year interval. The patterns had been constant:
- “What are my upstream and downstream dependencies?”
- “Is that this failure in my service, or is one thing I depend upon damaged?”
- “Which providers can be impacted if I take this down for upkeep?”
- “Why is that this service exhibiting as ‘Unknown’ in my metrics?”
- “What modified in my name path just lately that might clarify this habits?”
Engineers had been asking dependency questions continuously. We would have liked to supply solutions — rapidly, precisely, and in real-time.
Constructing on What We Discovered
We didn’t begin from scratch. Over time, we explored varied approaches to fixing this drawback — from evaluating exterior graph databases and vendor platforms to constructing inside prototypes with completely different storage applied sciences and knowledge fashions.
Every iteration taught us one thing priceless:
Actual-time issues: Dependency maps which might be hours outdated are ineffective in dynamic environments the place providers deploy a number of instances per day. We would have liked close to real-time updates.
Scale modifications the whole lot: Options that work at modest scale hit basic partitions at Netflix scale. Storage programs that deal with 1000’s of nodes battle with our service depend and visitors quantity.
Integration is vital: Any answer wants seamless integration with our present observability ecosystem. Engineers shouldn’t must be taught solely new instruments or depart their present workflows.
Knowledge high quality is vital: Incomplete or incorrect dependency data is worse than no data — it results in improper conclusions throughout incidents.
A number of views wanted: We discovered that no single supply of dependency data tells the entire story. Community connectivity knowledge lacks utility context. Utility metrics solely cowl instrumented providers. We would have liked to mix a number of sources.
These classes formed each resolution we made in constructing Service Topology.
What We Wanted: A Residing Map
We got down to construct one thing particular: a dwelling map of our infrastructure — one which updates in real-time as providers deploy, as visitors patterns shift, as new dependencies kind and outdated ones disappear.
The necessities had been clear:
Actual-time updates, not stale snapshots: In an surroundings the place providers deploy repeatedly, yesterday’s topology map is archaeology, not observability.
Quick queries at scale: When an engineer is troubleshooting at 3am, they will’t wait minutes for a question to return. We would have liked sub-second response instances for traversing the decision graph.
A number of layers: Community-level connectivity doesn’t inform the entire story. We would have liked to see each the community layer (what’s truly speaking to what) and the appliance layer (which APIs and endpoints are being referred to as).
Wealthy context, not simply connections: Realizing Service A talks to Service B isn’t sufficient. We would have liked to overlay well being standing, availability tiers, enterprise domains, possession data, and different metadata to make the data actionable.
Visible and programmatic entry: Engineers wanted a UI for exploration and troubleshooting. However automated programs — resilience frameworks, blast radius calculators, incident response automation — wanted programmatic API entry.
Our Strategy: Three Sources of Fact
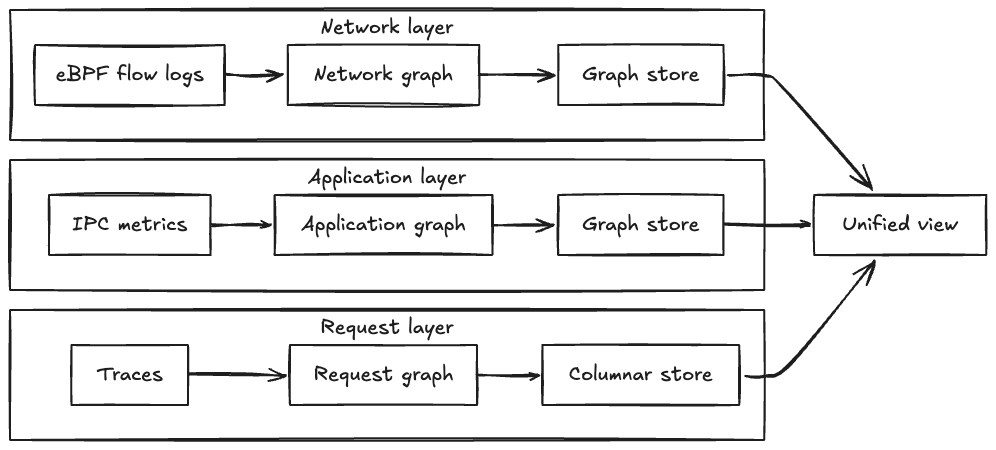
Right here’s the important thing perception we arrived at: no single supply tells the entire story.
We constructed Service Topology by utilizing three complementary sources to construct separate dependency graphs — one from every perspective — that may be mixed right into a unified view or explored independently:
Every supply creates its personal graph that’s bodily separate — the community layer in a single graph database partition, the IPC layer in one other partition, and the tracing layer utilizing columnar storage optimized for analytical queries. This bodily separation permits every layer to evolve independently and be queried in parallel. When customers request a unified view, we execute traversal queries throughout all layers concurrently and merge outcomes, reaching sub-second response instances even when combining all three layers.
Every supply creates its personal graph of service relationships:
1. eBPF Community Flows (Community Layer)
We seize community movement data on the kernel stage utilizing eBPF expertise — details about which providers are connecting to which different providers over the community. This provides us floor fact about precise network-level communication.
The worth: Complete protection. Each service reveals up right here as a result of we’re capturing precise community visitors, no matter whether or not purposes are instrumented. This layer gives topology at each cluster-level (which deployment clusters are speaking) and app-level (which purposes are speaking).
The limitation: Community-level data lacks utility context. We all know Service A related to Service B’s IP deal with utilizing a particular protocol, however not which particular API endpoint or path was referred to as (e.g., /api/v1/customers vs /api/v1/orders).
2. IPC Metrics (Utility Layer)
We accumulate Inter-Course of Communication metrics from our instrumented providers. These are the metrics purposes emit once they make calls to different providers through gRPC, GraphQL, REST, or different protocols.
The worth: Wealthy utility context. We are able to see which particular endpoints had been referred to as, error charges, latency distributions, protocol particulars, and request/response traits. This layer gives app-level topology — since IPC metrics are emitted by purposes, the pure granularity is application-to-application connections with endpoint particulars.
The limitation: Solely works for instrumented providers. If a service doesn’t emit IPC metrics, we gained’t see its application-level calls this approach.
3. Finish-to-Finish Tracing (Request Layer)
We combine distributed tracing data that follows particular person requests as they movement by way of our system. We combination traces to construct a unified topology graph, but additionally enable engineers to overlay particular person traces on the topology to see particular request flows.
The worth: Reveals precise request paths. Not simply “Service A can name Service B,” however “Service A did name Service B as a part of serving this particular member request.” This captures runtime habits, together with conditional logic and have flags. Engineers can each see the aggregated sample and drill into particular person traces. We combination traces to construct topology at each cluster-level and app-level, permitting engineers to view request patterns on the granularity most helpful for his or her investigation.
The limitation: Sampling. We are able to’t hint each request with out impacting efficiency, so we pattern. That is wonderful for understanding widespread flows, however could miss rarely-used code paths within the aggregated view.
Bringing It Collectively: Multi-Layer Structure
Right here’s what makes this highly effective: we construct three separate graphs — one from every supply — that create completely different views on service relationships:
- Community graph from eBPF flows: Each connection, no matter instrumentation
- Utility graph from IPC metrics: Wealthy endpoint and protocol particulars
- Request graph from tracing: Precise runtime habits and name paths
Engineers can:
- View every graph independently to concentrate on a particular perspective (pure community connectivity, application-level calls, or traced request flows)
- Mix them right into a unified graph by querying a number of partitions in parallel and merging outcomes — our system returns the union of nodes and edges from all requested layers whereas preserving every layer’s distinct properties
The unified view is very highly effective as a result of:
- Community flows guarantee completeness — we don’t miss something
- IPC metrics present utility particulars — we perceive the “how” and “what”
- Tracing reveals precise habits — we see actual request patterns
Every supply compensates for the constraints of the others. The result’s a complete, correct, and contextualized view of service dependencies that may be explored from a number of angles.
From Flows to Graph: How We Constructed It
Right here’s the high-level structure (we’ll dive deeper into engineering challenges in our subsequent publish):

Multi-Area Ingestion: We devour movement logs from Kafka throughout a number of AWS areas the place Netflix operates. This runs repeatedly, processing thousands and thousands of movement data as they arrive.
Distributed Processing: We use Apache Pekko Streams (a fork of Akka) to course of these flows in a distributed, fault-tolerant pipeline. The system robotically partitions work throughout our Auto Scaling Teams to deal with the amount and gives pure backpressure dealing with.
Three-Stage Distributed Aggregation: We combination community flows by way of a three-stage pipeline that solves a basic problem: community movement logs solely present particular person community hops by way of intermediaries (App A → Load Balancer → App B, or App A → NAT Gateway → App B), not the true application-level connections we’d like (App A → App B).
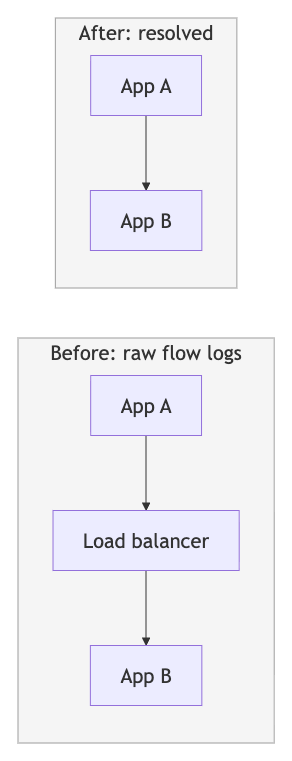
Stage 1 performs preliminary aggregation from Kafka. Stage 2 applies decision logic — figuring out community intermediaries (load balancers, NAT gateways, API gateways, proxies) and mixing their incoming and outgoing flows to reconstruct direct application-to-application paths. Stage 3 performs remaining aggregation with well being standing integration earlier than graph persistence. This graduated strategy additionally prevents sizzling spots by distributing load throughout a number of factors even when particular purposes or community intermediaries see 100x extra visitors than others.
Graph Storage: We persist the topology in Netflix’s graph database, an abstraction layer constructed on high of our distributed key-value storage infrastructure. This graph database is particularly designed for high-throughput graph operations at our scale, with quick multi-hop traversal capabilities. Every of our three knowledge sources (community flows, IPC metrics, tracing) creates a separate graph that may be queried independently or merged.
gRPC API: We expose the topology by way of a gRPC service that helps multi-hop traversal, filtering by availability tier and enterprise area, pagination for big consequence units, and sub-second question response instances.
The technical particulars of constructing this at Netflix scale — dealing with Kafka lag, managing reminiscence and rubbish assortment, optimizing distributed processing, debugging reactive streams — deserve their very own dialogue. We discovered lots, and we’ll share these classes in our subsequent publish.
What Engineers Can Do Now
Right now, the service topology map helps engineers throughout Netflix:
Visualize Dependencies: See upstream and downstream dependencies for any service, with the flexibility to filter by availability tier (Tier 0, Tier 1, and so on.) and enterprise area. Select between the unified view (combining all sources) or particular person graph views (network-only, IPC-only, or trace-only) relying on what you’re investigating.
Bounce to Detailed Indicators: From any service within the topology, rapidly navigate to logs, traces, and detailed metrics of their respective instruments. No extra trying to find the best service title or time window — the topology gives the context and the beginning level.
Perceive Blast Radius: Earlier than taking a service down for upkeep or making vital modifications, see precisely what can be impacted. Establish which groups to inform and what to monitor.
Overlay Well being Standing: See not simply the topology, however which providers within the name path are experiencing points. That is built-in with well being standing monitoring, so you’ll be able to rapidly determine if an issue you’re seeing is definitely originating elsewhere.
Question Programmatically: Use our gRPC API to combine topology data into automated programs. For instance, our Platform Modernization Engineering staff makes use of this to confirm that vital Reside providers have correct availability tier classifications all through their dependency chains.
Examine Quicker: Throughout incidents, rapidly determine if a failure is native or if it’s propagating from elsewhere within the name graph. Comply with the failure sample to seek out the foundation trigger.
Plan Adjustments Confidently: Perceive the influence of proposed architectural modifications or service migrations earlier than implementing them.
Time Journey Via Topology: Question what the topology appeared like at particular factors prior to now. Perceive what modified in dependencies across the time a problem began, or see how your service’s dependency footprint has advanced over time. This time-travel functionality is powered by time-window aggregation — as an alternative of storing each time slice individually, we use layer-specific aggregators that accumulate topology knowledge throughout home windows, permitting us to reconstruct historic views effectively with out exploding storage prices.
The Residing Map: All the time Present
What makes this actually helpful is that it’s a dwelling map. It’s not a static diagram drawn in a design doc that goes old-fashioned the second it’s printed. It’s repeatedly up to date based mostly on precise visitors:
- When a brand new service begins calling an API, it seems within the topology with close to real-time freshness
- When a service stops making calls to a dependency, that edge fades from the graph
- When providers deploy and their habits modifications, the topology displays it
- When incidents influence service well being, the standing overlay updates in real-time
This implies engineers can belief what they see. The map displays actuality, not somebody’s concept of what the structure ought to be.
The Journey Continues
We’re not performed. We proceed to evolve the system with new capabilities:
Change Occasion Overlay: We’re working to floor deployment occasions, configuration modifications, and different mutations alongside the topology graph. Correlation turns into simpler when you’ll be able to see each the dependencies and what modified when.
Richer Context: As we develop protection and combine extra indicators, we proceed to complement the topology with further endpoint-level particulars, protocol data, and community path context.
And looking out additional forward, we’re enthusiastic about one thing greater: Automated root trigger evaluation. Think about an clever agent that repeatedly crawls the topology graph, correlates failures throughout dependencies, understands historic patterns, and surfaces probably root causes robotically. Service topology gives the information graph basis that makes this sort of clever automation attainable.
Why This Issues for Our Members
This may appear to be infrastructure — plumbing that our members by no means see straight. However it issues immensely to their expertise.
When engineers can rapidly perceive dependencies and determine points, incidents get resolved quicker. Once we can mannequin blast radius earlier than making modifications, we keep away from disruptions. When automated programs can question dependency data programmatically, we are able to construct smarter, extra resilient programs.
All of this interprets to what issues most: our members getting to observe their favourite movies and collection, seamlessly, every time they need. Whether or not it’s a weekend binge of a beloved present, a stay sports activities occasion, or discovering one thing new by way of our suggestions tailor-made to their tastes — we wish it to simply work.
What’s Subsequent in This Collection
That is the primary in a collection of posts about constructing Service Topology at Netflix.
In our subsequent publish, we’ll pull again the curtain on the engineering challenges we confronted at scale: How do you deal with Kafka shopper lag when ingesting thousands and thousands of movement logs per second? What occurs when distributed processing meets rubbish assortment pauses? How do you debug reactive streams that stall beneath load? How do you handle sizzling nodes in a distributed system? We’ll share the true issues we hit in manufacturing and the options we developed.
In future posts, we’ll discover the teachings we discovered that apply to any distributed system at scale, and the place we’re heading subsequent with time journey capabilities and Automated root trigger evaluation.
Acknowledgements
This publish was written by Parth Jain.
Service Topology was constructed by Parth Jain, Rakesh Sukumar, Yingwu Zhao, Renzo Sanchez-Silva, and Nathan Fisher.
Particular because of the various engineers throughout Netflix who made this attainable — the Observability staff who constructed the broader system, the graph database platform staff who offered the storage basis, and the Platform Modernization Engineering, Reside, and Adverts groups who offered invaluable suggestions and use instances all through improvement.
![]()
From Silos to Service Topology: Why Netflix Constructed a Actual-Time Service Map was initially printed in Netflix TechBlog on Medium, the place individuals are persevering with the dialog by highlighting and responding to this story.