By Zhuoning Yuan, Ta-Ying Cheng, Benjamin Klein, Bahareh Azarnoush
Introduction
At Netflix, we construct know-how to assist storytellers convey their artistic visions to life and to assist members uncover the tales they love.
To attach tales with various audiences world wide, we produce promotional property, together with trailers, teasers, and social brief‑kind movies, that construct on and elevate the unique footage. By shut collaboration with the groups crafting these property, we recognized a recurring hole in present instruments. Reworking uncooked footage into a elegant ultimate asset typically requires complicated edits like seamlessly including new visible parts, patching or changing backgrounds, or eradicating undesirable objects with out breaking the scene’s bodily continuity. These duties usually demand hours of specialised guide modifying work. Whereas current generative video modifying fashions present promise, they typically wrestle to protect the integrity of the supply footage. Many strategies regenerate each pixel to make an edit, which might fail to isolate modifications and inadvertently alter parts that ought to stay untouched. To execute these duties successfully, artists want instruments that empower them to dictate precisely what modifications and the way it modifications.
Our analysis purpose is to make this course of simpler for artists. We’re deliberate about the place and the way AI is utilized, guaranteeing that the know-how all the time serves the artistic intent. That precept drives our current work: exploring the advantages of generative AI in ways in which shield and increase artistic selection, and protecting artists in exact management of their ultimate imaginative and prescient. Latest developments in AI video modifying have demonstrated spectacular capabilities in streamlining complicated guide modifying workflows, however key challenges stay earlier than they will reliably help skilled use:
- Unintended edits: When modifying a particular component in a video clip, many strategies regenerate the whole video, which might inadvertently alter id, efficiency, and different parts like objects, backgrounds, or crucial scene particulars.

- Unnatural physics: When eradicating objects, many strategies focus solely on erasing the goal whereas ignoring the scene’s bodily continuity. This may result in inconsistent movement and implausible interactions, making the outcomes look unnatural.

As we speak, we’re sharing two analysis explorations that purpose to handle these challenges. We consider this work may also help advance the sphere in a manner that’s each significant and accountable:
- Vera: a layered video diffusion mannequin. Vera generates solely what wants to alter as separate edit layers whereas leaving the remainder of the video untouched, preserving the identities, performances, and different particulars from the supply footage precisely as filmed.
- VOID: a video inpainting mannequin for video object and interplay deletion. VOID performs bodily believable inpainting in complicated scenes: it doesn’t simply take away an object, but in addition reconstructs the scene as if the thing was by no means there.
Together with this weblog publish, we’re additionally publicly releasing the analysis papers that element the algorithmic improvements behind Vera and VOID. We hope these publications will allow different researchers to experiment with these concepts, construct upon our findings, and additional advance the subject.
Vera: A Layered Video Diffusion Mannequin
Present video modifying fashions regenerate the whole clip, coupling the meant edit with areas that ought to stay unchanged. This will increase the danger of altering particulars of the unique footage. To deal with this problem, we introduce Vera, a novel layered video diffusion framework for content-preserving video modifying.

Inference Pipeline
Given a supply video and a textual content modifying instruction, Vera collectively generates an edit layer and an alpha matte. These layers are then seamlessly composed with the unique footage to supply the ultimate edited end result. By design, Vera helps complicated duties corresponding to object addition and background change, whereas guaranteeing that the pixels outdoors the edited areas from the supply video stay completely intact.
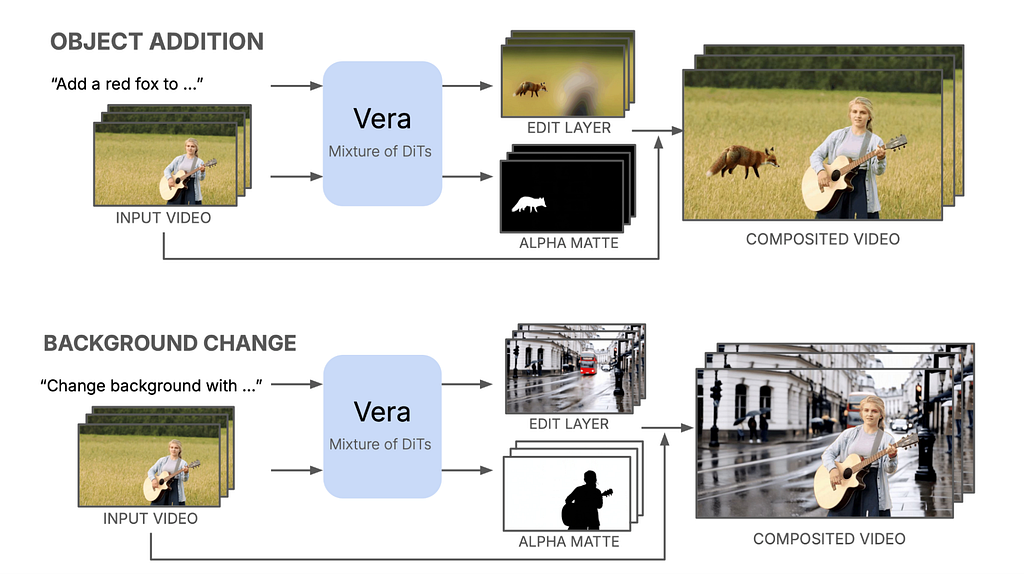
Coaching Knowledge
One of many major challenges in creating Vera was the dearth of appropriate coaching knowledge. Since no public dataset offers the high-quality layered knowledge we want (clear enter, alpha matte, edit layer, composite video), we constructed our personal. Utilizing a mix of present open-source movies and human annotation, we constructed a layered video dataset with a complete of 486k frames at 832×480 decision. We organized it into three subsets of accelerating complexity:
- Artificial Composites: Clips with high-quality foreground alpha mattes are composited over various, routinely generated backgrounds. This subset offers robust and dependable supervision for alpha matting in object addition and background change duties.
- Practical Single-Object Movies: Actual-world clips are processed via segmentation, matting, background inpainting/technology, and human high quality filtering. This subset will increase scene range and digicam movement, bettering composition high quality throughout each duties.
- Practical Multi-Object Movies with Results: This extends the earlier subset by isolating particular person objects with curated alpha mattes, together with their related results corresponding to shadows and reflections. This subset improves compositing and modifying in additional complicated, dynamic scenes.
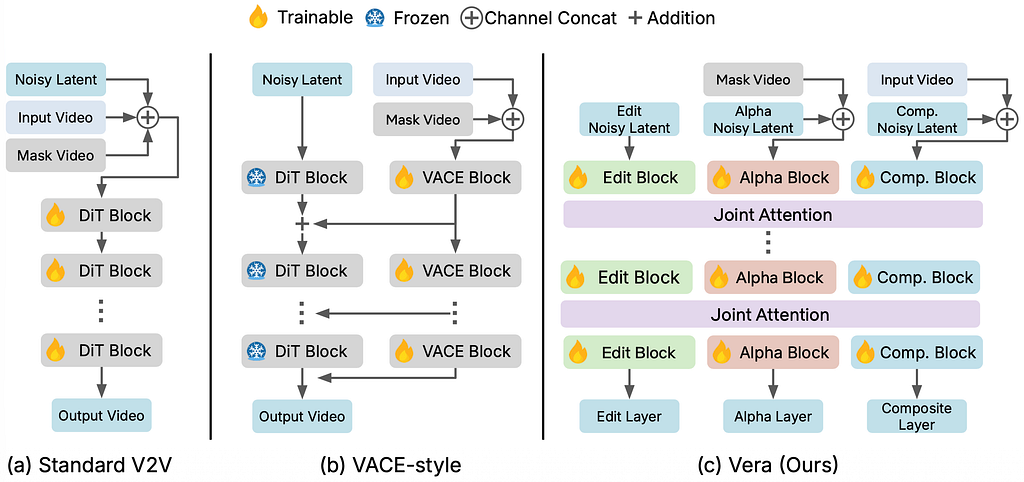
Mannequin Structure
Past knowledge, mannequin design is one other key problem. The three goal outputs Vera generates — an edit layer (decoupled artistic edits), an alpha matte layer (a grayscale masks that is dependent upon the edit content material and scene interactions corresponding to occlusions), and a composite layer (pure footage) — have considerably totally different distributions. In apply, utilizing a single shared structure to reconcile these variations proved data-inefficient. To deal with this, Vera makes use of a MoT (Combination-of-Transformers) design. As an alternative of a single DiT, we use three separate DiTs, one for every output:
- Every DiT maintains its personal QKV projections and FFN weights, however we concatenate the output tokens from all three branches after which cross it to joint self-attention. This permits cross-layer interplay whereas permitting every department to specialize.
- All three DiTs are initialized from the identical pretrained T2V base mannequin. We add two further patch-embedding layers for the enter video and an elective masks video. Supply-video tokens are added to the composite tokens, whereas masks tokens are added to the noisy alpha tokens.
- All layers share the identical RoPE (Rotary Positional Encoding). We additionally add zero-initialized learnable embeddings to the alpha and composite tokens to assist the mannequin distinguish between layers.
Evaluations and Outcomes
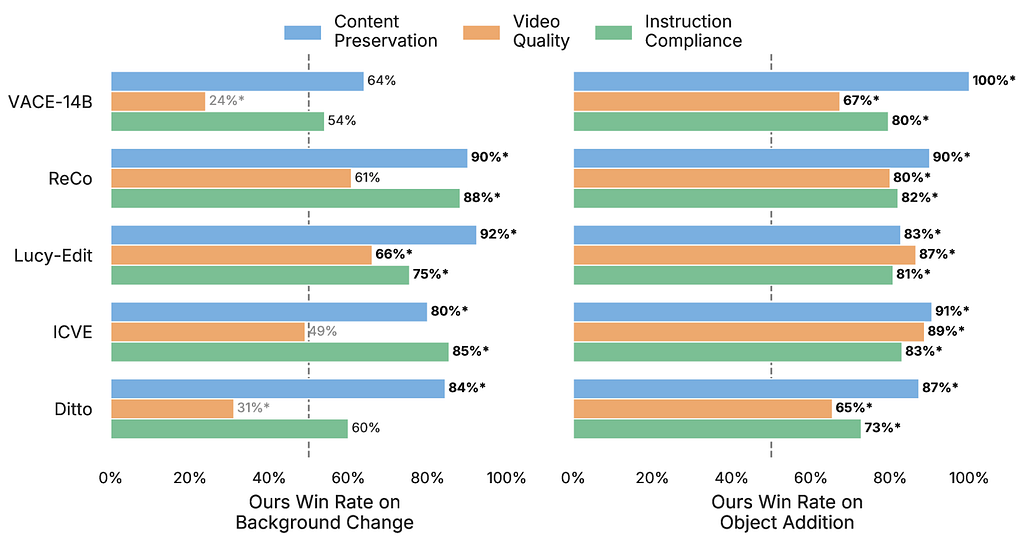
To guage Vera, we curated a benchmark of check video-prompt pairs: 72 for object addition and 69 for background change, utilizing open-source movies. The check set spans a variety of issue, together with gradual and quick motions, numerous digicam motions, single and a number of objects, and each easy and sophisticated scenes. We evaluated the efficiency throughout three complementary dimensions:
- Content material Preservation: Measures whether or not areas outdoors the focused edit stay strictly unaltered, evaluated utilizing pixel-level and perceptual similarity.
- Instruction Compliance: Measures how faithfully the edited video executes the textual content immediate.
- Video High quality: Assesses the temporal coherence and per-frame spatial high quality of the ultimate edited video.
In our outcomes, each Vera-1.3B and Vera-14B considerably outperform present baselines on content material preservation, whereas sustaining related video high quality and instruction compliance efficiency in comparison with strongest baselines (please see the paper for full outcomes).

To enhance automated metrics, we ran a human desire research evaluating Vera in opposition to 5 baselines. We collaborated with 19 artistic reviewers who evaluated 512 video trials in whole. In every trial, reviewers have been proven randomized side-by-side comparisons between the Vera mannequin and a baseline mannequin. The human consensus strongly aligned with our quantitative findings: Vera-1.3B was most well-liked over all baselines for content material preservation and instruction compliance. Moreover, reviewers rated Vera’s video high quality as similar to baselines on background change duties, and famous a transparent benefit for Vera on object addition duties.
VOID: Video Object and Interplay Deletion
Present video object removing strategies excel at inpainting content material “behind” the thing and correcting appearance-level artifacts corresponding to shadows and reflections. Nonetheless, when the eliminated object has extra vital interactions — corresponding to collisions with different objects — present fashions fail to appropriate them and produce implausible outcomes. To deal with this, we current VOID, a video object removing framework designed to carry out physically-plausible inpainting in these complicated eventualities.

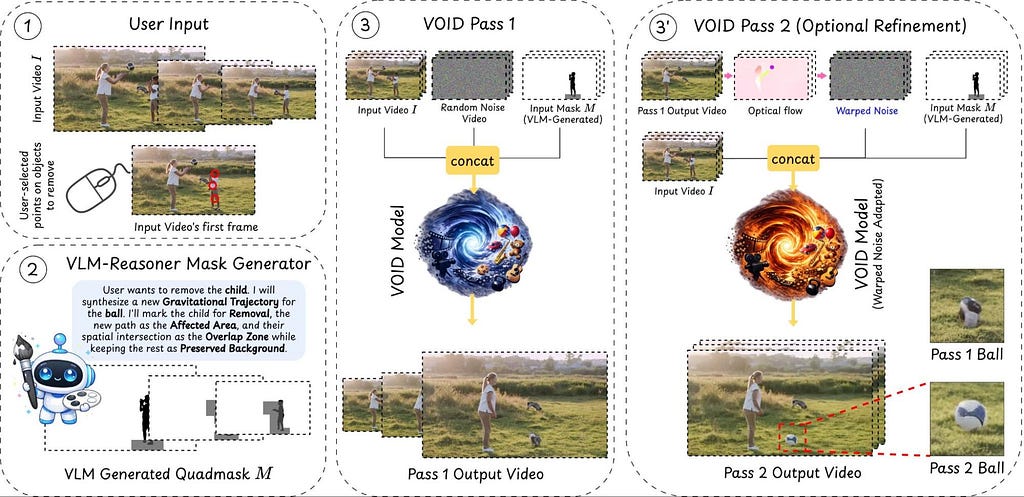
A Two-Move Inference Pipeline
Given an enter video, the consumer clicks on an object to take away. A VLM-based reasoning pipeline then analyzes the scene to establish different areas that shall be causally affected, e.g., objects that can fall, collide, or change trajectory. This bodily reasoning is encoded right into a quadmask to information the diffusion mannequin:
- First Move: VOID takes the video and the quadmasks as enter and generates a bodily believable counterfactual video by which the thing — and its interactions — are eliminated.
- Second Move: Smaller video diffusion fashions sometimes endure from “object morphing” when producing shifting objects. If VOID detects this failure mode, it triggers a second cross that re-runs inference utilizing flow-warped noise derived from the primary cross, stabilizing the thing’s form alongside its newly synthesized trajectory.
Coaching Knowledge
We constructed on high of the Kubric simulation engine and the HUMOTO human movement seize dataset to generate artificial counterfactual video pairs together with their corresponding quadmasks. Particularly, the counterfactual movies are generated by re-simulating the precise scene from the unique video, however with the goal object(s) or human eliminated. This resimulation creates an alternate consequence primarily based on strict legal guidelines of physics. For instance, if an individual holding a lamp is faraway from the scene, the simulation ensures the lamp obeys gravity and falls to the bottom. The quadmasks then seize the eliminated object (black), the affected areas (gray), their overlaps (darkish gray), and the unchanged components of the scene (white).

Mannequin Coaching
Throughout mannequin coaching for VOID, we introduce two enhancements over prior work: (i) quadmask conditioning, which explicitly identifies areas in every body which will change after the thing is eliminated, and (ii) a second-pass video look refiner that reduces artifacts corresponding to undesirable object morphing. VOID is lastly educated on the CogVideoX-Enjoyable-V1.5–5b-InP spine with Gen-Omnimatte’s checkpoint and fine-tuned for video inpainting with interaction-aware quadmask conditioning.
Evaluations and Outcomes
Experiments throughout each artificial and actual knowledge exhibit that VOID preserves constant scene dynamics much better than prior video object removing strategies (please see the paper for full outcomes). VOID efficiently maintains object construction and produces believable movement over time throughout all kinds of real-world instances. In contrast, outcomes from each open- and closed-source baselines constantly exhibit bodily inaccurate artifacts. As an example, baselines generate water splashes with out human influence (see high row of the determine under) or present spinning tops being disrupted with out the presence of interacting arms.

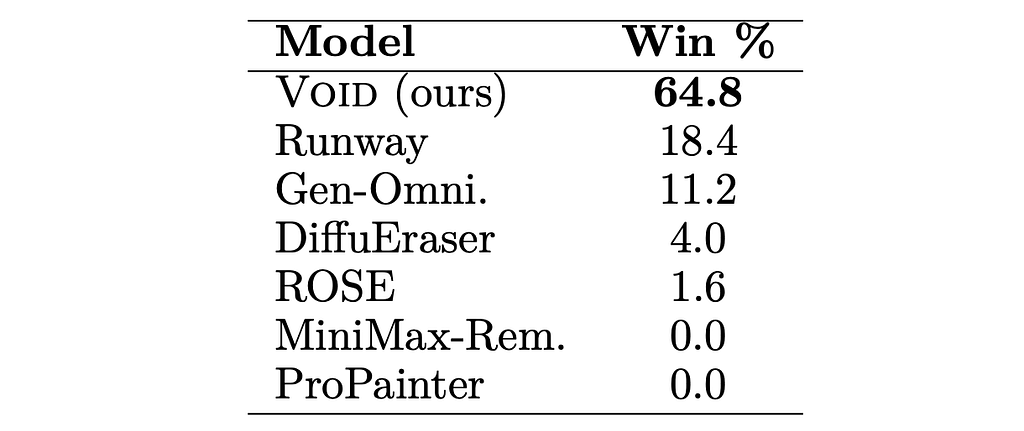
To enhance our quantitative analysis, we carried out a consumer research with 25 artistic reviewers to measure the perceptual realism and bodily plausibility of our counterfactual edits. Every participant was randomly assigned 5 out of 75 real-world eventualities, leading to 125 whole comparisons. For every video, individuals seen the unique enter alongside the outputs of VOID and 6 baselines (seven fashions whole) in a randomized order. Contributors have been requested to pick out the video that finest mirrored how the scene ought to realistically seem after the thing was eliminated, factoring in visible high quality, temporal consistency, mixing, the realism of scene evolution, and the absence of artifacts. VOID was chosen 64.8% of the time, considerably outperforming all baseline fashions.
Wanting Forward
Making use of AI in ways in which serve each member and creator wants is core to our analysis philosophy, and these initiatives mirror that method. Whereas Vera and VOID present promising early outcomes, reaching production-ready high quality would require addressing a number of limitations we encountered. For instance, Vera struggles with some complicated results corresponding to lightning or smoke as a result of restricted coaching knowledge, and in some instances, it fails to maintain background movement totally per the enter digicam motion. Regardless of the assorted generalization capabilities VOID reveals, we nonetheless observe area gaps. As an example, it can not deal with movies with uncommon digicam angles or photographs captured very near the goal object, and it at present has constraints on supported video size and backbone.
These limitations encourage continued funding on this line of analysis. Vera and VOID are necessary early efforts towards making complicated video modifying extra controllable and accessible for artists. For this work, we used publicly accessible datasets with further annotation efforts for experiments, and we hope that sharing our analysis will encourage the broader group to construct on these concepts and advance them additional.
![]()
Towards Extra Controllable AI Video Modifying: An Early Analysis Exploration at Netflix was initially printed in Netflix TechBlog on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.