By Guil Pires, Jennifer Prince, Jose Camacho, Ken Kurzweil, Phanindra Chunduru
Background
In a earlier submit, we launched Knowledge Bridge, a unified administration airplane for batch Knowledge Motion at Netflix. Traditionally, a number of bespoke Knowledge Motion connectors had been developed throughout totally different engineering organizations to satisfy their particular necessities. Over the previous few years, the Knowledge Motion staff has began centralizing these choices by an abstraction that gives a catalog of connectors, together with easy UI and APIs to provoke Knowledge Motion jobs.
One such case is the Cassandra to Iceberg connector. Apache Cassandra powers mission vital purposes at Netflix, together with Member, Billing, Suggestions, Subscriptions and plenty of extra. These use instances closely leverage Knowledge Motion to Apache Iceberg for a lot of analytics and operational duties, and central to this motion was a connector for Cassandra to Iceberg constructed in-house named Casspactor. As many Cassandra primarily based Knowledge Abstractions emerged, similar to Key Worth, Time Sequence and Graph — the necessity for bigger and extra complicated Knowledge Motion with transformations turned extra vital to the enterprise.
Knowledge actions are basically fulfilled by leveraging the prevailing Cassandra backup infrastructure. Frequently scheduled backups are carried out straight on the Apache Cassandra nodes, by way of a sidecar course of managing the add of all essential SSTables and related Metadata recordsdata straight into Amazon S3. When a Knowledge Motion job is initiated, the job constructs the precise backup construction it wants by referencing the S3 primarily based metadata, permitting it to exactly find the SSTable recordsdata. The engine then downloads these recordsdata, performs the required mutation compaction and processing, and eventually writes the totally remodeled, compacted knowledge straight into the goal Apache Iceberg tables.

Casspactor: The Engine We Outgrew
Casspactor processed roughly 1,200 knowledge actions per day, transferring roughly 3 PB of knowledge from Apache Cassandra into Apache Iceberg tables. It served a number of the most crucial workloads at Netflix. For years, it labored. Then, two compounding challenges made it clear we wanted a basically totally different structure.
Fragile Metadata Dependencies
Earlier than Casspactor may transfer a single file, it wanted to reply a deceptively easy query: which backup exists, is it full, and what does it comprise?
Casspactor assembled this reply from a number of impartial methods:
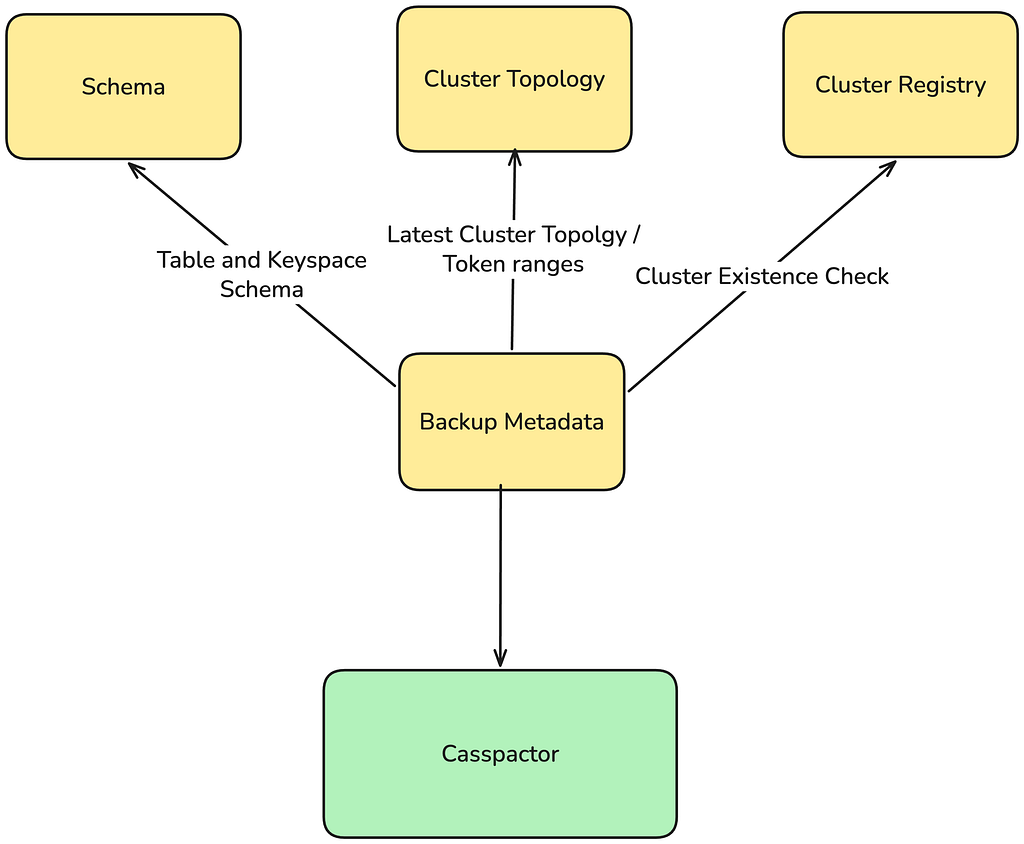
Every system had its personal failure modes, replace cadences, and accuracy ensures. Casspactor’s view of the world was a composite, and composites diverge from actuality.
Metadata fell out of sync with precise backups, inflicting Casspactor to learn stale or incorrect knowledge silently. Routine upkeep on the Cassandra Clusters triggered uncoordinated snapshots, and since Casspactor required all nodes in a area to snapshot on the identical clock second, a single node alternative may break knowledge motion for a whole area.
The repair was hiding in plain sight. The reply to “which backup exists and is it full?” already lived within the backup storage layer (Amazon S3) itself. By studying metadata straight from the backup recordsdata, we may change your complete dependency chain with a single supply of reality.
Each Connector Inherited Casspactor’s Limitations
Cassandra at Netflix doesn’t simply retailer uncooked tables. It backs increased degree knowledge abstractions, similar to Key Worth, Time Sequence, and others, every with its personal knowledge mannequin, entry patterns, and semantics. When any of those abstractions wanted to maneuver knowledge to Iceberg, all of them funneled by Casspactor.
Each abstraction inherited Casspactor’s constraints:
- Skewed partition failures: Casspactor couldn’t deal with tables with giant partitions, a typical sample in Key Worth and Time Sequence workloads. Jobs crashed with out-of-memory errors on a few of Netflix’s largest datasets.
- No knowledge mannequin consciousness: Casspactor moved uncooked Cassandra tables as is. Connectors for Key Worth and different abstractions needed to bolt on submit processing to reconstruct their knowledge fashions from the uncooked output — additional price, additional complexity, and an additional floor for failures.
- Intermediate desk bloat: Casspactor wrote to an intermediate Iceberg desk earlier than producing the ultimate output. The Key Worth connector added one other intermediate desk and a snapshots desk. Connectors for abstractions on high of Key Worth added much more. This compounded into important storage price overhead.
- Lack of ability to Time Journey: by counting on a number of companies to compose a backup unit, Casspactor was unable to revive prior backups within the occasion of cluster Topology or Keyspace schema modifications.
- Monolithic design: Casspactor was constructed as a single connector, not as an engine. There was no method to construct a household of objective constructed connectors on a shared basis.
We would have liked one thing basically totally different: an engine that reads straight from backups in S3, produces normal Spark DataFrames, and lets every knowledge abstraction construct its personal connector with full consciousness of its knowledge mannequin. One basis, many connectors.
The New Stack: A Layered Structure
The brand new structure, constructed upon the muse of Apache Cassandra Analytics and the in-house Transfer Knowledge framework, represents a basic shift towards a layered, purpose-built stack designed for reuse and maintainability. This new engine was conceived with clear separation of issues, shifting away from Casspactor’s monolithic design. The structure is deliberately layered with the muse being a core S3 studying functionality: the Cassandra Analytics Wrapper, which is constructed on high of the Open Supply Cassandra Analytics with Netflix’s inside backup illustration and an S3 Consumer.
This layer handles the uncooked knowledge retrieval from backups, translating it into normal Spark DataFrames. Sitting atop this basis is a “Connector Manufacturing facility” mannequin, by way of each Java UDFs and transforms which permits particular person knowledge abstractions (Key Worth, Time Sequence, others) to construct extremely optimized, knowledge mannequin conscious connectors that course of the generic Spark DataFrames, avoiding the necessity for complicated, costly, and failure-prone post-processing steps. This layered method ensures that enhancements to the core studying engine profit all connectors, whereas the connectors themselves are centered solely on knowledge transformation.
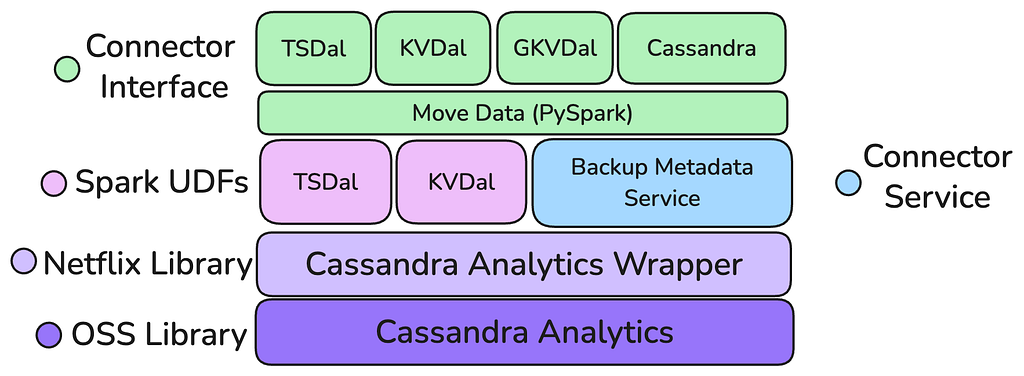
- Handles Skewed Partitions: By shifting the mutation compaction and processing to the Executor degree inside Spark, the brand new engine can effectively deal with tables with extremely skewed or large partitions, a serious ache level for Casspactor. Crucially, this processing happens with out extreme knowledge shuffling, stopping out-of-memory errors and enabling dependable motion of Netflix’s largest datasets.
- Operates at Spark DataFrames (No Middleman Tables): The brand new structure straight generates normal Spark DataFrames from the Cassandra backups. This eliminates the necessity for Casspactor’s pricey, multi-stage intermediate Iceberg tables, which led to storage bloat and operational complexity. This native DataFrame operation allows the “Connector Manufacturing facility” by offering a common, simply consumable interface for constructing numerous, mannequin particular connectors.
- Jobs Auto Measurement: The engine integrates clever auto-sizing capabilities, permitting jobs to dynamically alter useful resource consumption primarily based on the supply desk’s traits. This removes the burden of handbook tuning from engineering groups, making certain optimum efficiency and price effectivity with out sacrificing reliability.
- Diminished Dependencies: By studying metadata straight from the backup recordsdata saved in S3, the brand new stack removes the delicate, multi-service dependency chain that plagued Casspactor. S3 turns into the only, authoritative supply of reality for backup existence and completeness, vastly bettering knowledge motion reliability and consistency.
- Time Journey: A vital characteristic of the brand new stack is the power to course of the schema, cluster topology, and knowledge as a cohesive unit at a selected cut-off date. This functionality supplies strong time journey performance, important for auditing, debugging, catastrophe restoration and reproducing previous knowledge states.
- Efficiency: Collectively, these architectural enhancements, together with native DataFrame processing, optimized partition dealing with, and streamlined metadata retrieval have resulted in notable efficiency positive factors, lowering total knowledge motion execution runtime and price in comparison with the legacy Casspactor system.
- Price: by eliminating middleman Iceberg tables and environment friendly SSTable compaction on Executors, the brand new stack wants a considerably smaller storage and compute footprint resulting in important price financial savings within the order of USD tens of millions.
The Journey In the direction of a Protected Migration
The profitable validation of the brand new stack was the vital first step, but it surely solely marked the start of probably the most difficult section: the migration. Massive scale knowledge migrations are inherently complicated, high-risk undertakings that may be time consuming and sometimes lead to buyer frustration and repair disruption. To navigate the excessive stakes of decommissioning a mission-critical system like Casspactor and seamlessly changing it, we wanted a technique that prioritized reliability and transparency above all else.
The migration was basically enabled by a Like-for-Like technique, which served because the cornerstone of our Platform Engineering philosophy, abstracting complexity. The core tenet was to take care of absolute consistency throughout the user-facing interface, the output contract, and the ultimate knowledge artifact. This meant making certain that the info motion parameters outlined by way of the Knowledge Bridge abstraction remained unchanged, and, critically, the schema, metadata, and knowledge inside the vacation spot Iceberg tables had been an identical to the legacy output. By preserving these exterior contracts, we eradicated the necessity for complicated, time-consuming coordination with dozens of inside groups who relied on these knowledge pipelines. This method remodeled the migration from a distributed, high-risk, multi-team effort into an inside platform implementation element, permitting us to attain a clear, zero-impact transition and speed up the retirement of the legacy system with out requiring any code modifications or validation from downstream customers.
To navigate this migration, we developed a technique anchored by three core pillars that function a blueprint for profitable, large-scale knowledge migrations:
- Validation: Establishing and sustaining absolute confidence in knowledge consistency by rigorous, ongoing validation.
- Visibility: Instrumenting each a part of the system to offer a transparent, real-time understanding of migration progress and system well being.
- Security: Guaranteeing consumer influence is minimized or eradicated, regardless of the inevitable system failures, by leveraging abstractions and strong fallbacks.
The following part will present an in depth exploration of those key pillars.
Pillar 1: Validation
Belief is earned, and in knowledge migration, it’s earned one row at a time. The primary pillar is probably the most vital: offering a measurable assure to customers and companions that the info produced by the brand new system is a precise, row-by-row reproduction of the info produced by the outdated one.
Our foundational tactic was deploying the brand new Transfer Knowledge connector in a “shadow” testing that ran in parallel with the manufacturing Casspactor jobs. This allowed us to validate the brand new system with real-world, manufacturing workloads with none buyer influence.
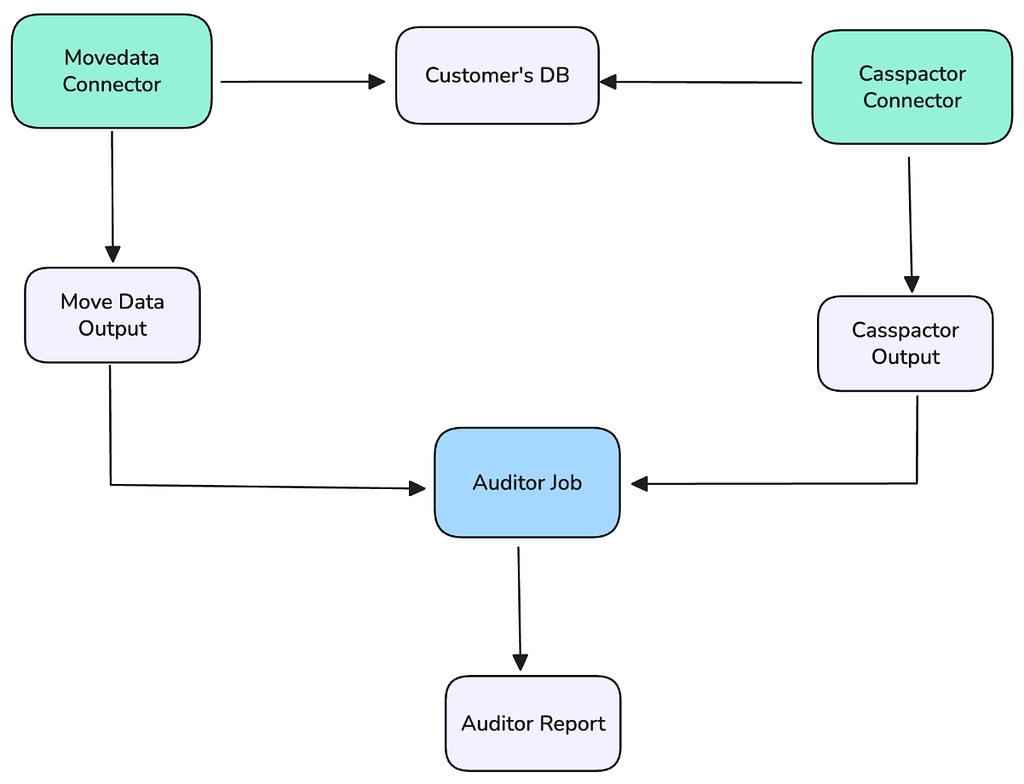
- Let C be the set of rows within the legacy Casspactor output (Iceberg desk).
- Let M be the set of rows within the new Transfer Knowledge output (Iceberg desk).
The take a look at for belief: show that C = M. This required repeatedly checking for 2 circumstances:
- Rows in C however not in M (C-M): The brand new system missed knowledge.
- Rows in M however not in C (M-C): The brand new system launched phantom or inaccurate knowledge.
Any end result the place the cardinality of those distinction units (the variety of differing rows) was larger than zero triggered a direct, high-priority investigation. The goal was 100% similarity.
Uncovering and Resolving Disparities
The shadow mode rapidly turned a robust forensic instrument, exposing “unknown unknowns”, refined discrepancies that weren’t bugs within the new system however quite variations in habits between the brand new and outdated methods. Resolving these was the core work of constructing belief. For every downside we initiated an investigation log the place we captured the small print, logs, queries that allowed us to diagnose. Primarily based on the evaluation the problems had been categorized in order that related variations on different datasets had been later resolved affecting most of the shadow pipelines.
Sustaining an investigation log was vital to arrange the excellent points and successfully talk to stakeholders the progress and confidence of the brand new connector in order that we successfully measure the suitable degree of “confidence” to provoke the migration.
We noticed variations in how connectors leverage reference timestamps for Time-to-Dwell, Consistency Ranges, backup choice, and varied inside enterprise logic. This steady, data-driven cycle of discovery and backbone was the mechanism by which we constructed confidence within the new structure.
Pillar 2: Visibility
Belief is constructed within the background, however an lively migration requires real-time perception: Visibility. The second pillar entails instrumenting the system to offer an unambiguous, clear understanding of operational well being and migration progress.
We prolonged our instrumentation to the general migration workflow and its dependencies:
- Dashboards: We created centralized dashboards to trace migration standing, visualizing the entire variety of knowledge actions migrated versus these remaining. The dashboards tracked execution standing, common runtime, and price comparisons between the 2 connectors.
- Dependency Monitoring: Because the new system relied on a brand new set of APIs to fetch backup metadata, we carried out detailed metrics for failures to maintain monitor of the APIs or dependencies failed.
- Alerting: Proactive alerts had been arrange for job failures (Transfer Knowledge or Casspactor), failures on Transfer Knowledge that triggered a fallback to Casspactor or any knowledge discrepancy being detected.
This complete instrumentation allowed the staff to be proactive, repair points as they emerged through the migration, and acquire the required confidence to speed up the migration timeline.
Pillar 3: Security
Even with excellent knowledge correctness and enhanced visibility, the third pillar, Security is required for a zero-impact migration. The problem is making certain that when a system inevitably fails, the consumer expertise is uninterrupted. Our technique centered on decoupling the consumer’s workflow from the underlying connector implementation.
Leveraging Abstraction: The Decider Sample
To realize a clear swap, we leveraged the Maestro workflow orchestration platform to implement the Decider sample:
- Knowledge Motion Abstraction: From a consumer’s perspective, their Knowledge Motion job definition remained the identical.
- The Decider Step: Internally the workflow accountable to execute the job was modified to incorporate a Decider step. This step took the info motion parameters (supply cluster, desk identify, vacation spot) and invoked a management airplane: Connector Controller.
- Connector Controller because the Registry: The management airplane served because the dynamic registry. Primarily based on the migration cohort and the info motion attributes, it decided and reported the suitable connector to make use of both Casspactor (legacy) or Transfer Knowledge (new).
This abstraction gave our staff full management. We may improve or rollback any connector for any knowledge motion immediately by merely updating a configuration within the controller, with zero modification required to the 1000’s of downstream buyer workflows. Crucially, this abstraction assured the vital security web: a conditional step within the Maestro workflow logic ensured that if the Transfer Knowledge step fails, it could instantly execute the Casspactor step.
This sample would improve the possibilities that the consumer’s knowledge motion completes efficiently, even when the brand new connector encountered a bug or transient failure through the preliminary rollout phases. Consumer influence was utterly eradicated; they may see a barely longer runtime within the occasion of a failure and fallback, however they’d by no means see a migration failure or endure from stale knowledge.
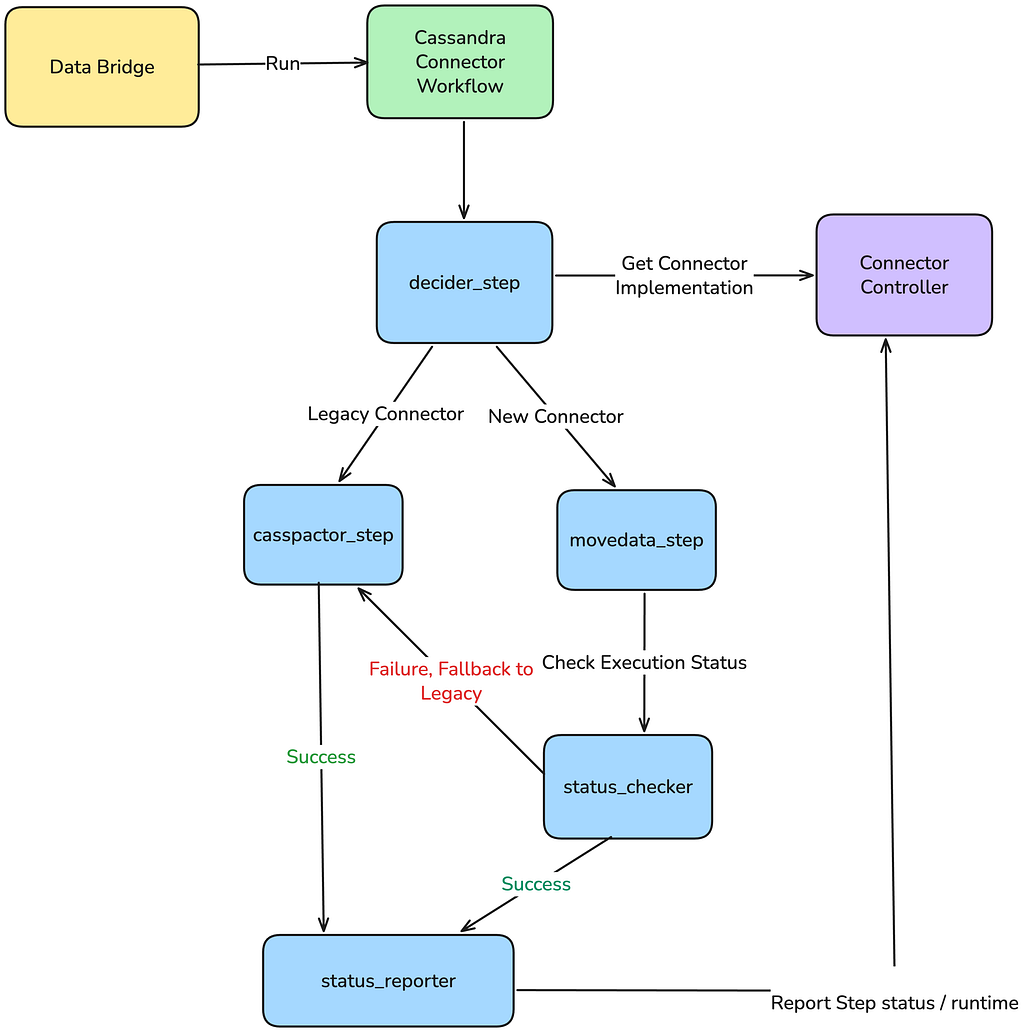
Past the workflow, the brand new system structure itself was inherently extra resilient. By constructing the brand new knowledge motion connector on Cassandra Analytics and studying backups straight from S3, we eliminated fragile dependencies on deprecated inside companies.
Conclusion
The migration from Casspactor to the brand new, layered structure constructed on Cassandra Analytics and the Transfer Knowledge connector was greater than a typical “tech debt” mission; it was a basic shift in our method to knowledge motion reliability and scalability at Netflix.
The legacy system, whereas serving us effectively for years, was in the end constrained by monolithic design, fragile metadata dependencies, and an incapacity to deal with the complexity of recent knowledge abstractions. The brand new stack resolves these points by delivering a strong, cost-efficient, and inherently extra resilient resolution that reads straight from S3, handles large partitions gracefully, and eliminates pricey intermediate tables.
Our blueprint for the migration, anchored by the three pillars of Validation, Visibility, and Security, ensured a clear and high-confidence transition. By way of rigorous shadow testing and a data-driven audit framework, we achieved the specified knowledge consistency. Enhanced dashboards and alerting offered the real-time operational perception essential to handle threat. Most critically, the implementation of the Decider sample inside our workflow abstraction minimized the influence for all downstream customers.
This profitable migration validates a core philosophy: by abstracting complexity on the platform degree, we are able to carry out giant system migrations with out burdening our product engineering companions. The brand new basis is now able to help the subsequent technology of Netflix’s knowledge abstractions.
Trying forward
This foundational work on the Cassandra Knowledge Motion stack has performed extra than simply change a legacy system: it has turn into an accelerator for innovation throughout your complete Knowledge Motion group. By offering a dependable, performant engine that standardizes knowledge retrieval into Spark DataFrames, we’ve enabled the fast improvement of latest, extremely optimized connectors. This new “Connector Manufacturing facility” method has already delivered a devoted Key-Worth to Iceberg and Time Sequence connectors, each of that are totally conscious of their respective knowledge fashions, eliminating pricey post-processing. This structure can be paving the best way for formidable new initiatives, together with the event of an answer for bulk loading knowledge into Cassandra itself, successfully finishing the info motion cycle, and enabling safer fleetwide connector rollout with canaries impressed by the Decider Sample.
We’re extremely grateful for the in depth collaboration among the many Knowledge Motion, Knowledge Bridge, On-line Knowledge Shops, Membership, Billing, Subscriber and Advertisements platform groups at Netflix; this work merely couldn’t have been achieved with out their partnership!
![]()
The Evolution of Cassandra Knowledge Motion at Netflix was initially printed in Netflix TechBlog on Medium, the place individuals are persevering with the dialog by highlighting and responding to this story.