Authors: Lequn Wang, Jiangwei Pan, and Linas Baltrunas

Introduction
The Netflix homepage is the very first thing customers see once they open the app and the first method they uncover content material to take pleasure in. Virtually each a part of it’s customized, together with which rows seem, which entities present up inside these rows, and the way all the pieces is organized on the web page.
Developing that homepage is a genuinely onerous downside. It isn’t merely producing one ranked listing. The homepage is a structured, two-dimensional format, made up of advice rows and the entities inside them. Right here, an entity could be a film, present, sport, dwell occasion, or different recommendable merchandise. Every alternative can have an effect on the worth of the others. Historically, it’s constructed via a posh, multi-stage pipeline, with separate parts for candidate era and rating at each the row and entity ranges.
We noticed a chance to rethink this design. Massive language fashions have proven {that a} single generative mannequin can carry out numerous duties simply by producing a response to a immediate. Impressed by this prompt-response paradigm, we skilled a single generative mannequin to construct the homepage by immediately answering one query:
Given all the pieces we learn about this person and this request, what homepage ought to we generate to maximise person satisfaction?
We name this method GenPage. It treats the person historical past and request context because the immediate, and autoregressively generates your complete homepage because the response (Determine 1). Not like most generative recommenders, comparable to TIGER, HSTU, and OneRec, which generate flat ranked lists, GenPage generates the rows, entities, and format collectively.
This shift is motivated by a number of targets:
- Finish-to-end modeling. A single transformer mannequin that constructs the web page from uncooked enter indicators can exchange a posh multi-stage recommender stack. This reduces the variety of ML fashions to keep up, avoids misaligned targets throughout phases, and eliminates a lot of the standard function engineering.
- Complete-page optimization through reinforcement studying (RL). Autoregressive web page era makes it attainable to optimize for page-level rewards with RL. This will seize interactions throughout rows and entities, comparable to variety or the steadiness between rows with totally different stopping energy. For instance, a Proceed Watching row close to the highest of the web page could strongly fulfill a person’s quick intent, but in addition cut back how a lot of the web page they browse. Modeling these interactions on the web page degree lets us align the system extra immediately with person satisfaction than entity-level targets alone.
- Higher scaling habits. A generative transformer mannequin provides us a clearer path to bettering high quality via extra information, compute, and mannequin capability, with out repeatedly redesigning the system.
- Flexibility and extensibility. The prompt-response paradigm is versatile by design. By simplifying function engineering and enabling whole-page optimization, GenPage makes it simpler to assist new product experiences, comparable to extra content material varieties like dwell occasions, video games, and podcasts; layouts past the present two-dimensional construction; customized UI parts; and per-entity paintings personalization, all with fewer architectural adjustments.
Bringing GenPage into manufacturing at Netflix additionally required fixing challenges particular to industry-scale recommender programs. As a result of the homepage is generated in actual time, serving latency is a major engineering constraint. We additionally have to deal with entity chilly begin in a continually evolving catalog, hold the mannequin recent as person pursuits and cultural developments shift, and implement advanced product and enterprise guidelines on the generated output.
Regardless of these challenges, GenPage has already had substantial manufacturing influence. In a web based A/B check towards a mature, extremely optimized multi-stage manufacturing recommender, GenPage delivered statistically vital good points on the core person engagement metric we use for launch selections, whereas decreasing end-to-end serving latency by 20%.
Offline, two findings stood out. First, enriching the immediate helped greater than scaling mannequin capability in our present regime. Second, RL post-training elevated homepage variety though variety was not a part of the target.
We count on this method to generalize to many personalization settings. On this submit, we give attention to Netflix homepage development as a concrete case research, sharing our design, trade-offs, and classes discovered.
Knowledge
Transferring from a conventional recommender to a generative transformer requires us to rethink how the info is represented. Just like how an LLM turns textual content into tokens, GenPage represents each the person context and the generated homepage as one sequence of discrete tokens (Determine 2). This sequence consists of the complete structured homepage format, with a number of rows and the entities inside them, so the mannequin can generate the web page holistically fairly than scoring every row or entity in isolation.
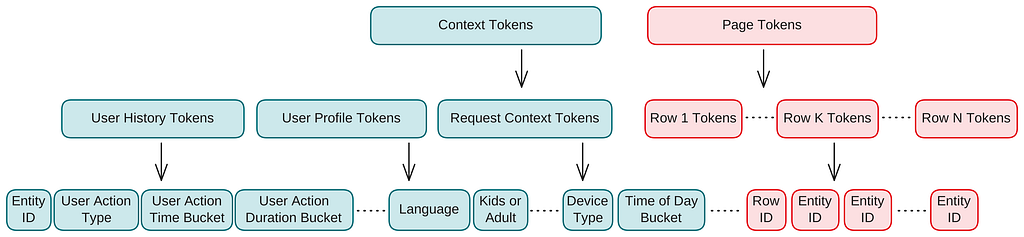
Every coaching instance represents a homepage impression and consists of three parts:
- Context: person engagement historical past, profile attributes, and request context.
- Web page: the advisable rows and entities proven on the homepage, in format order.
- Suggestions: person interactions with that web page, comparable to play, thumbs-up, or abandonment for entities on the web page.
Solely the context and web page are tokenized as mannequin inputs and outputs. Suggestions is used to derive supervision indicators through our inside reward system (see the Reward system part).
As an alternative of utilizing an off-the-shelf textual content tokenizer, we construct a domain-specific tokenizer for the homepage development information. This can be a confirmed method in recommender programs and different specialised domains together with pc imaginative and prescient, biology, and chemistry, the place the uncooked information is just not naturally represented as textual content. In contrast with generic textual content tokenization, this offers us two key benefits:
- Computational effectivity. Customized tokenization considerably reduces sequence size, reducing inference price and latency. For instance, representing the occasion “Consumer watched Orange Is the New Black for 50 minutes 30 days in the past.” would require 16 tokens with the GPT-5 tokenizer, whereas our scheme compresses it to 4 tokens: [Entity_ID], [Action_Type], [Action_Time_Bucket], and [Action_Duration_Bucket].
- Product management. A direct mapping between tokens and product ideas, comparable to rows and entities, makes it simpler to regulate what the mannequin can generate. That is essential for imposing enterprise guidelines on the ultimate homepage.
Context tokens
Context tokens encode person engagement historical past, person profile, and request context.
We signify person historical past as a sequence of person actions. For every motion, we extract key metadata, together with the motion sort, entity ID, timestamp, and length. These actions embrace each specific indicators, comparable to play, add to My Checklist, and thumbs-up, and implicit indicators, comparable to trailer views or visits to a particulars web page.
Consumer profile tokens seize attributes comparable to language and profile sort. Request context tokens encode indicators like time of day, day of week, and gadget.
Some information sources are too lengthy to incorporate immediately as uncooked token sequences. A person’s full impression historical past, for instance, could be prohibitively costly to signify in full. In these instances, we use a summarized model. This can be a pragmatic trade-off: whereas GenPage goals to function on uncooked inputs as a lot as attainable, handcrafted summaries nonetheless introduce a type of immediate engineering into the pipeline. Studying to compress these lengthy information sources finish to finish is a crucial course for future work.
To assist the mannequin distinguish between information sources, we insert particular tokens that mark the beginning of every section. Steady indicators, comparable to timestamps and durations, are bucketized into discrete ranges to maintain the vocabulary finite.
Web page tokens
Every entity, comparable to a present, film, or sport, and every row, comparable to Korean TV Reveals, is represented as a single token. The homepage is serialized in format order: left to proper, then prime to backside. We replace the entity and row vocabulary each day to include newly added entities and rows. Entities which can be nonetheless out of vocabulary at serving time are dealt with via semantic embedding fusion and fallback tokens, each described later.
In precept, the identical paradigm can lengthen to any output that may be expressed as a linear token sequence. This consists of layouts past the present two-dimensional construction, comparable to one-dimensional feeds or combined layouts, in addition to customized UI parts and per-entity outputs comparable to customized paintings. We depart these extensions to future work.
Paginated suggestion
To make suggestions aware of in-session person preferences, the homepage is commonly generated incrementally, just a few rows at a time. Earlier than every pagination request, we append the web page tokens from beforehand generated rows to the immediate, together with the person’s newest engagements on these rows from Netflix’s real-time event-logging infrastructure. This permits the mannequin to generate the following set of suggestions utilizing each the person’s long-term preferences and their most up-to-date in-session habits.
Reward system
To quantify the long-term worth of a suggestion, we depend on an inside reward system described in prior work. The reward system is tuned via on-line A/B testing to align with long-term person satisfaction and serves as the first supervision sign for each supervised and reinforcement studying.
The reward system processes person suggestions and assigns a scalar reward for each impressed entity on the homepage. As an illustration, a TV present binge-watched in a single night time displays stronger person satisfaction and receives the next reward than a film watched for less than 10 minutes. An impressed entity that the person abandons receives a adverse reward.
We outline the page-level reward because the sum of rewards throughout all impressed entities on the homepage.
Mannequin structure
GenPage makes use of a typical decoder-only transformer structure, the identical basic structure behind many fashionable LLMs. This alternative retains the mannequin easy and versatile, whereas additionally letting us profit from the broad ecosystem of tooling round transformer coaching and serving.
One architectural element is that we untie the enter embedding and output projection weights. That is helpful as a result of pretraining and post-training place totally different calls for on the logits. Subsequent-token prediction pretraining optimizes a softmax over the vocabulary, whereas weighted binary classification (WBC) post-training optimizes per-token sigmoid scores, as described beneath. Untying the weights provides the mannequin extra flexibility to adapt to each targets.
Coaching recipe
Our coaching pipeline mirrors the LLM recipe: we first educate the mannequin the “language” of the Netflix homepage via pretraining, then align its outputs with person satisfaction via post-training. For post-training, we discover two various approaches: weighted binary classification (WBC) and reinforcement studying (RL).
WBC is less complicated to optimize and aligns immediately with the entity-level targets of our manufacturing rating fashions. RL is tougher to guage and optimize, however it’s the key path to GenPage’s full imaginative and prescient of page-level optimization, with the pliability to include test-time reasoning and multi-token entity representations.
Pretraining through next-token prediction
We pretrain the mannequin with a typical next-token prediction goal: given the context tokens and a prefix of web page tokens, the mannequin learns to foretell the following web page token. This stage focuses on illustration studying, instructing the mannequin the connection between person contexts and profitable homepages. Word that our context-page coaching examples resemble the prompt-response pairs utilized in LLM supervised fine-tuning (SFT) greater than the uncooked textual content utilized in LLM pretraining. We nonetheless name this stage pretraining as a result of we practice the mannequin from scratch fairly than fine-tuning from an present checkpoint.
Not like LLMs, which regularly face a shortage of high-quality labeled information, recommender programs have an abundance of person suggestions. For pretraining, we use homepage impressions that acquired optimistic suggestions when served in manufacturing, bootstrapping the mannequin to generate pages much like these produced by the present manufacturing system.
Nevertheless, pretraining primarily teaches GenPage to mimic the manufacturing system. It doesn’t immediately optimize the magnitude of the reward, and as GenPage turns into a part of manufacturing, repeatedly coaching on pages generated by earlier variations of the mannequin can threat mannequin degeneration. To handle these limitations, we discover two post-training approaches.
Publish-training through weighted binary classification
One efficient option to align the generative mannequin with person satisfaction is weighted binary classification (WBC). At a excessive degree, WBC turns era into token-level worth prediction: given the person context and the tokens generated to this point, the mannequin learns to estimate the worth of producing every attainable subsequent row or entity token.
This goal is simpler to optimize than page-level RL. By decomposing the homepage into per-token targets, WBC gives token-level credit score task by development, fairly than requiring RL to deduce how every generated resolution contributed to the ultimate page-level reward.
This coaching setup is enabled by our customized tokenization. Every web page token corresponds on to a selected entity or row, making it simple to assign a reward. For each impressed entity on the web page, our reward system gives a scalar reward primarily based on person suggestions. For every impressed row, we derive a row-level reward by aggregating the rewards of the entities in that row.
From every reward, we derive a binary label from its signal, comparable to optimistic engagement versus abandonment, and a weight from its magnitude, comparable to binge-watching receiving the next weight than a brief play. We then optimize a weighted binary cross-entropy loss on the logit for the corresponding token. Below this setup, the logit for a token might be interpreted because the mannequin’s worth estimate for producing that token at that place.
Though the mannequin is skilled as a worth predictor, it might nonetheless generate pages autoregressively. At every step, the mannequin scores the candidate subsequent tokens, greedily selects the token with the best worth, and appends it to the prefix. This course of repeats token by token till the complete homepage is generated.
Publish-training through reinforcement studying
Our second post-training method is reinforcement studying (RL). WBC is efficient for optimizing entity-level metrics, nevertheless it doesn’t immediately optimize the homepage as a complete. RL treats web page era as a sequential decision-making downside, permitting the mannequin to optimize a page-level reward whereas preserving the pliability of autoregressive era.
This opens the door to a number of necessary capabilities:
- Complete-page optimization. RL immediately optimizes an combination page-level reward, permitting the mannequin to account for interactions throughout rows and entities, comparable to variety, stopping energy, and page-level enterprise constraints.
- Check-time reasoning. Analogous to its utility in LLMs, RL can optimize reasoning capabilities for generative suggestion. Reasoning outputs may also be considered as a type of automated function engineering.
- Multi-token entity assist. In our present tokenization, every entity and row is represented as a single token, so rewards map cleanly to particular person tokens. In additional advanced settings, nonetheless, an entity could require a number of tokens, comparable to [Show_ID] plus [Episode_#] for an episode, or a sequence of semantic ID tokens. In that case, WBC’s per-token labeling turns into ambiguous as a result of a single entity-level reward have to be distributed throughout a number of tokens. RL avoids this difficulty by optimizing the sequence-level return, making it a extra pure match for variable-length, multi-token entities.
Impressed by the RLHF recipe used to align massive language fashions, we undertake a two-step method. First, we practice a reward mannequin that predicts the page-level reward for a generated web page. This reward mannequin is distinct from the reward system described earlier. The reward system converts noticed person suggestions right into a scalar reward for a web page that was really proven, whereas the reward mannequin predicts the page-level reward for a generated web page with out displaying it to the person. This prediction is what lets RL optimize towards arbitrary candidate pages throughout coaching.
Coaching towards a reward mannequin avoids the excessive variance of off-policy correction on logged or predicted propensities, however introduces the chance of reward hacking. For the reason that reward mannequin is skilled on information generated from the manufacturing coverage, it’s most dependable on pages much like these the manufacturing coverage generates. We subsequently use a KL penalty to maintain the coverage near the pretrained checkpoint, which itself was skilled to imitate the manufacturing coverage. This retains the pages inside the reward mannequin’s area of protection and limits alternatives for reward hacking.
For the RL algorithm, we undertake Dr. GRPO, a variant of GRPO that mitigates biases within the coaching goal. To coach the mannequin inside this framework, we’d like the next parts:
- Prompts: manufacturing person requests, represented by context tokens.
- Coverage and reference fashions: each are initialized from the pretrained checkpoint; the reference mannequin anchors the KL penalty mentioned above.
- Reward mannequin: a devoted transformer-based reward mannequin, additionally initialized from the pretrained checkpoint, predicts the page-level final result reward, utilizing the sum of entity-level rewards from our inside reward system because the supervision goal. We additionally incorporate rule-based format rewards to information the RL coverage. For instance, the web page ought to resemble a listing of rows, and business-critical rows or entities mustn’t seem too low on the web page.
Addressing manufacturing challenges
Chilly begin
New entities lack the wealthy interplay information wanted to be taught sturdy token embeddings. We handle this via two complementary methods:
- Context injection. We inject metadata about new or time-sensitive entities (e.g., Reside Now occasions) immediately into the context tokens, offering the mannequin with semantic and time-sensitive info.
- Semantic embedding fusion. Reasonably than relying solely on entity ID embeddings discovered from person interplay information, we signify every entity as a fusion of its ID embedding and a content-based embedding derived from semantic info comparable to synopses, forged, transcripts, genres, and video content material. This fused embedding serves because the enter embedding for the entity’s token within the transformer. Throughout coaching, with small likelihood, we randomly exchange an entity ID token with the generic fallback token (described beneath), so the mannequin learns to make suggestions from the content-based embedding alone. This ensures {that a} new entity has a significant illustration in the identical latent house as established entities as quickly as its content material metadata is obtainable — even earlier than it has any interplay information.
Multi-cadence incremental coaching
At Netflix scale, each day retraining of a big transformer from scratch is prohibitively costly, however suggestion fashions should stay recent to seize shifting developments and new catalog additions. We handle this with a multi-cadence incremental coaching technique (Determine 3).
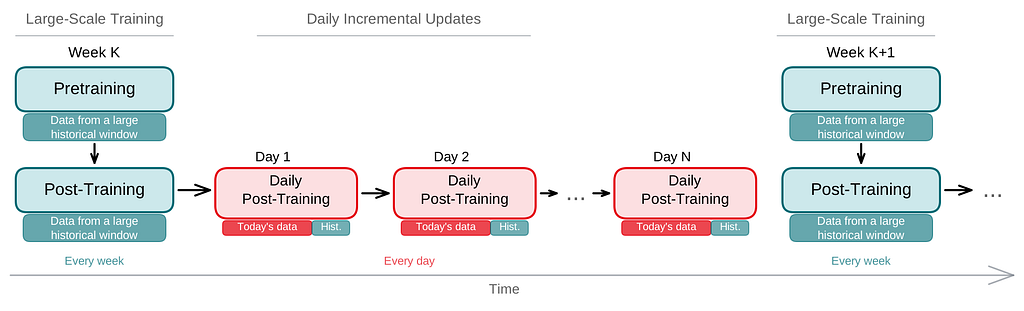
Our coaching pipeline operates on a cyclic schedule with two distinct rhythms. At a tunable cadence, we conduct a large-scale pretraining and post-training move on information from a broad historic window. Between these passes, every day we carry out an incremental replace by persevering with post-training from the day before today’s checkpoint, utilizing a mixture of the newest day’s information and a sampled subset of previous information. This helps the mannequin keep present with new developments and catalog adjustments whereas stopping overfitting and catastrophic forgetting.
To handle the each day inflow of latest tokens (e.g., new entities, rows), we make use of fallback tokens. New tokens are initialized utilizing fallback tokens of their sort (e.g., [Row_Fallback_Token] for brand spanking new rows, [Entity_Fallback_Token] for brand spanking new entities). Throughout coaching, we randomly exchange a small share of recognized tokens with fallback tokens, instructing the mannequin to deal with unknown tokens gracefully.
Imposing enterprise guidelines
A Netflix homepage should fulfill structural constraints (e.g., organized as a listing of rows) in addition to product logic comparable to deduplication, row pinning, and class consistency (e.g., entities in a Comedy row have to be comedies). Whereas coaching indicators can encourage rule adherence, they can’t assure strict compliance.
We implement these guidelines at inference time via constrained decoding. At every autoregressive era step, we compute a masks of eligible tokens primarily based on the relevant enterprise guidelines and apply it to the output logits, permitting solely rule-compliant tokens to be generated. That is drastically simplified by our customized tokenization: as a result of every entity and row is a single token, enterprise guidelines map on to token-level masks, avoiding the multi-token bookkeeping that constrained decoding requires over a textual content vocabulary. For instance, to pin a selected row (e.g., in style video games) at a set place (e.g., row place 2), we merely masks out all different tokens at that place.
Hybrid row decoding
Autoregressive era ensures that every newly generated token is conditioned on the complete previous context, however producing each entity token separately might be costly. We leverage the construction of the homepage to steadiness inference effectivity with the quantity of contextual info out there to every generated token.
Inside every row, the primary few entities are particularly necessary: they obtain essentially the most person consideration and strongly form the row’s perceived high quality and theme. To cut back inference latency, we use a hybrid row decoding technique. The mannequin autoregressively generates solely the primary few entities in every row. Conditioned on this generated prefix, we get hold of logits for all eligible entities in a single ahead move and choose the top-scoring remaining entities, topic to the identical inference-time business-rule constraints described above.
This method preserves autoregressive conditioning the place it issues most whereas avoiding the latency and value of decoding lengthy rows token by token.
Offline experiments
We ran a collection of ablations on Netflix inside information to grasp how totally different parts of GenPage have an effect on mannequin high quality. As a result of the system was developed iteratively, particular person ablations span totally different coaching configurations and information snapshots, so we report solely relative comparisons inside every research. Except in any other case famous, experiments use ~200M-parameter fashions and report outcomes on a held-out analysis set.
Does pretraining assist?
We examine WBC post-training with and with out a previous next-token-prediction pretraining stage. Determine 4 exhibits that pretraining yields substantial enhancements throughout all metrics.
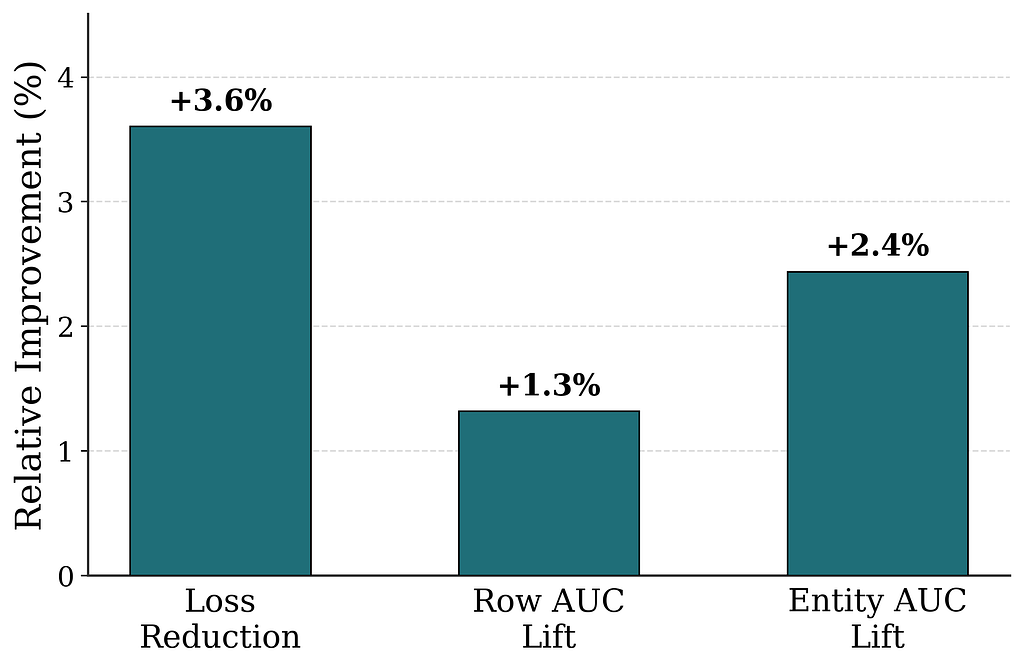
The good points could look small in absolute phrases, however they’re massive in our manufacturing regime: setting apart the pattern weighting, an Entity AUC carry from 0.91 to 0.92 implies that for a randomly drawn pair of impressed entities, the mannequin’s misranking price drops from 9% to eight% — a magnitude of enchancment we not often observe from a single change on a mature manufacturing system. Pretraining the mannequin on the “language” of the Netflix homepage gives a powerful initialization for post-training, mirroring the pretrain-then-post-train recipe behind fashionable LLMs.
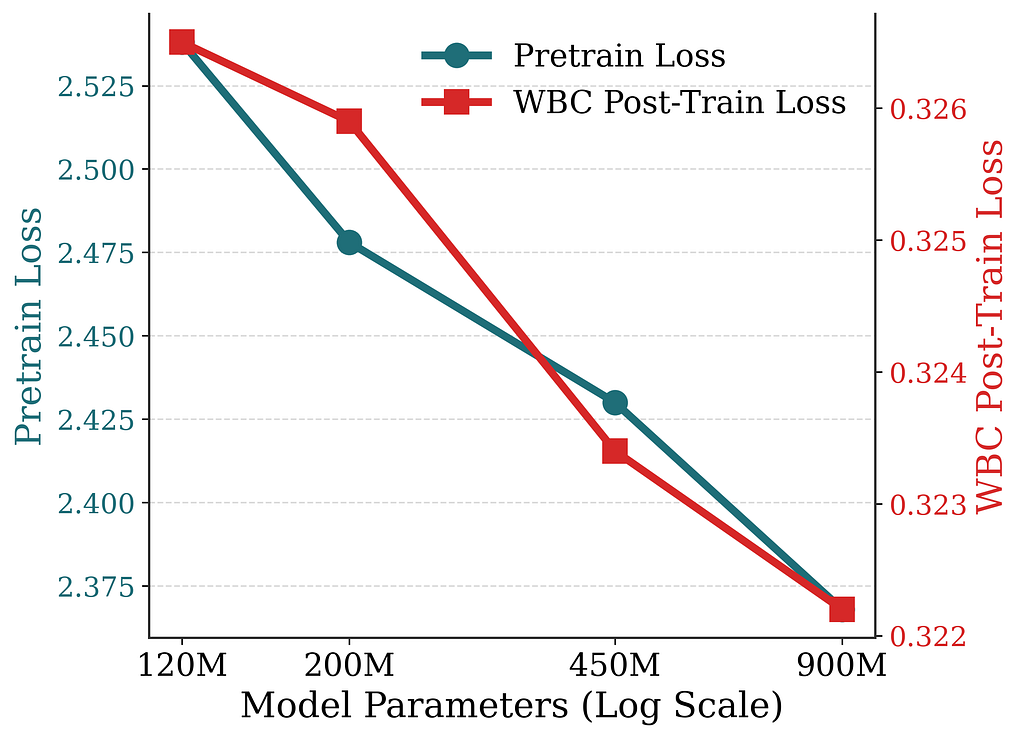
How does efficiency scale with mannequin measurement?
We sweep mannequin measurement from ~120M to ~900M parameters (Determine 5) and report the next-token-prediction loss from pretraining and the WBC loss from post-training. Each losses lower in a power-law-like vogue, mirroring the scaling developments seen in LLMs. This confirms that the generative method scales favorably with mannequin measurement, suggesting that suggestion high quality might be additional improved by scaling capability.
How does efficiency scale with info within the person context?
Over the course of improvement, we progressively enriched the immediate, each by including new information sources to the context and by refining how every supply is tokenized. With mannequin measurement held mounted, the WBC post-training loss decreases considerably because the context is enriched (Determine 6).
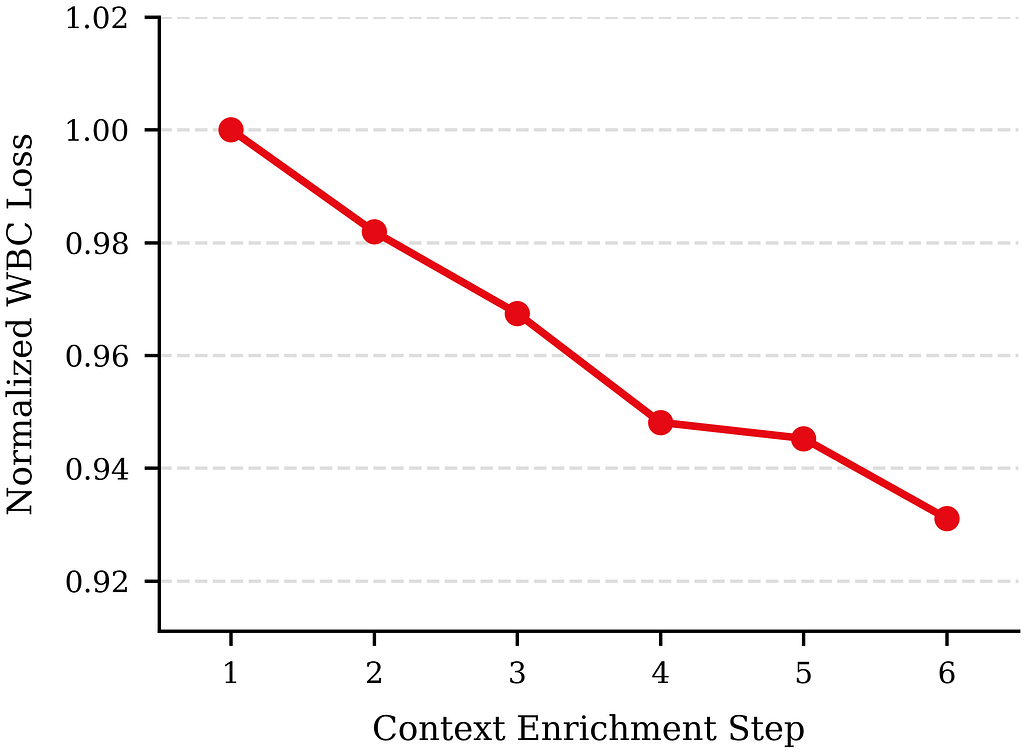
The model-size sweep and the context-enrichment sweep span totally different axes and aren’t strictly comparable: the model-size research covers roughly an order of magnitude in parameters, whereas the context research spans the complete trajectory of our immediate design. Even so, the hole between the 2 is placing. Scaling the mannequin from 120M to 900M parameters reduces WBC loss by roughly 1.3%, whereas the cumulative impact of enriching the context is round 6.9%. In a number of instances, a single well-designed context addition delivers a bigger enchancment than your complete ~7.5× model-capacity scaling.
This implies that, in our regime, enriching the immediate — each what we put within the context and the way we tokenize it — yields a considerably bigger enchancment than scaling mannequin capability. Personalization high quality seems to be bottlenecked first by the knowledge and illustration out there to the mannequin, and solely then by capability. We count on context enrichment to dominate till the context is saturated, at which level mannequin capability turns into the first driver.
Does RL post-training optimize on the web page degree?
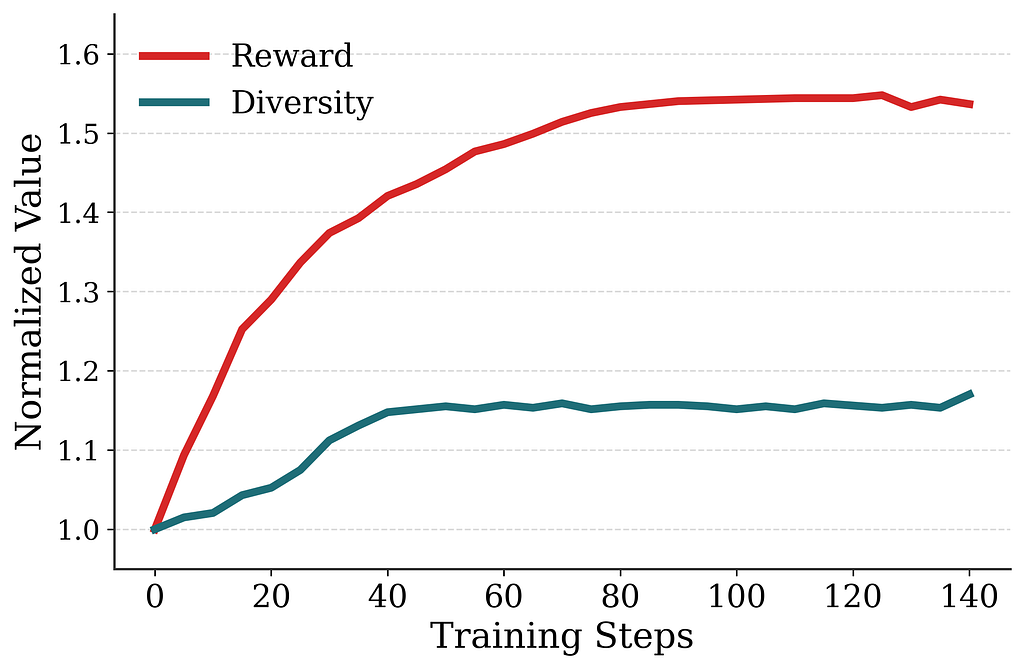
In offline evaluations (Determine 7), RL post-training persistently improves the page-level reward over the pretrained checkpoint, however that is largely confirmatory: the reward is computed utilizing the identical mannequin the coverage is optimizing towards. Extra curiously, though variety is just not a part of the RL goal, homepage variety — measured through pairwise embedding distance amongst entities on the web page — additionally will increase over the course of coaching. This implies that the RL-trained coverage is optimizing the web page as a complete fairly than myopically optimizing every token in isolation.
On-line analysis
We performed a web based A/B check towards the present manufacturing homepage recommender utilizing GenPage. On this check, GenPage decoded over the present manufacturing row and entity candidate units, which assist deal with many enterprise guidelines (comparable to eligibility).
Determine 8 exhibits the end result: all variants delivered statistically vital enhancements on the core person engagement metric we use for launch selections (p < 0.001) towards a mature, extremely optimized multi-stage manufacturing baseline. The variants differed of their training-data configurations; that all of them delivered comparable lifts suggests the achieve is strong to those design selections fairly than depending on a selected configuration.
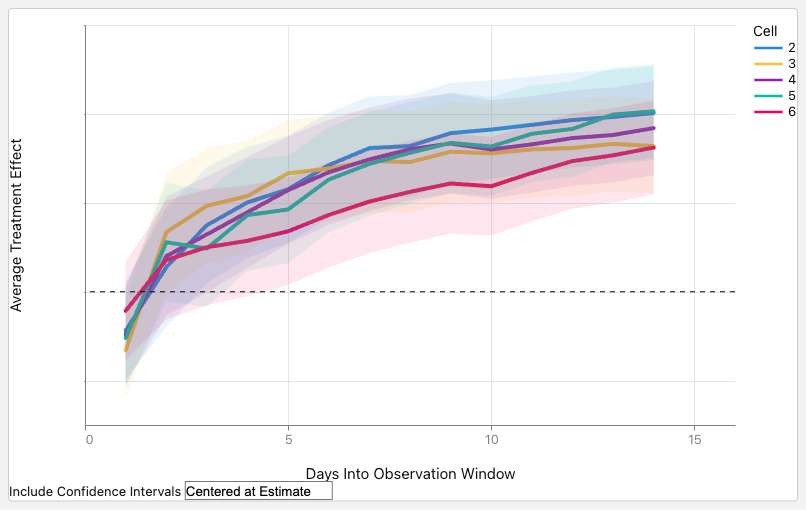
Alongside the engagement wins, we noticed unintended shifts within the distribution of impressed entity classes (e.g., new vs. established titles, TV exhibits vs. films). These shifts aren’t essentially adverse, however they aren’t one thing we explicitly optimized for, and so they warrant deeper investigation. We suspect these shifts mirror GenPage personalizing extra exactly than the manufacturing stack — in step with a rise in homepage impression effectivity, i.e., customers partaking with what they noticed utilizing fewer impressions. This sharper personalization seems to floor production-inherited parts (such because the reward system) that aren’t but aligned with the brand new generative paradigm. We plan to characterize the drivers of those shifts and, the place acceptable, tune these parts so the ensuing distributions higher align with desired product habits.
We additionally noticed robust responsiveness to in-session indicators: the newest in-session actions rapidly influenced subsequent suggestions and pale again to long-term preferences after a day or two, confirming that the mannequin successfully attends to motion timestamps. This responsiveness emerges naturally from the generative formulation, with out the intensive guide function engineering utilized in our manufacturing stack.
Opposite to the widespread assumption that generative fashions are slower, GenPage lowered end-to-end serving latency by 20% relative to the baseline. By changing a number of rating phases and heavy function computation with a single transformer working on uncooked tokenized inputs, we eradicated substantial serving complexity and computational overhead. Customized tokenization and hybrid row decoding additional lowered the variety of decoding steps, and thus latency. The 20% discount was achieved with out exhausting the out there optimizations; additional reductions are attainable, and this headroom might be reinvested in capability or richer prompts.
Conclusion
We offered GenPage, an early step towards end-to-end generative Netflix homepage development: representing person context as a tokenized immediate and producing your complete homepage autoregressively in actual time. This collapses the standard multi-stage recommender stack right into a single transformer that may be optimized end-to-end.
In on-line A/B checks towards a mature, extremely optimized multi-stage manufacturing system, GenPage delivered statistically vital good points on the core person engagement metric we use for launch selections, whereas decreasing end-to-end serving latency by 20%. Attaining this required adapting the LLM coaching recipe — pretraining adopted by WBC or RL post-training — along with a set of domain-specific methods: customized tokenization for serving effectivity and product management, context injection and semantic embedding fusion for entity chilly begin, multi-cadence incremental coaching for mannequin freshness, constrained decoding for business-rule enforcement, and hybrid row decoding for inference effectivity.
Two offline findings stand out. First, in our present regime, enriching the immediate yields a considerably bigger enchancment than scaling mannequin capability — a takeaway we count on to generalize to different industry-scale personalization settings, at the very least till the out there context is totally exploited. Second, RL post-training will increase homepage variety though variety is just not a part of the target — a sign that page-level optimization captures interactions throughout rows and entities.
A number of items of the complete imaginative and prescient are nonetheless in progress: lengthy context nonetheless depends on handcrafted summarization, and broader LLM-style capabilities — language, multimodality, and reasoning — haven’t but been included. One promising course here’s a hybrid tokenization combining our domain-specific tokens with generic textual content tokens, retaining structured management whereas inheriting the strengths of general-purpose LLMs; conceptually, this introduces a further suggestion modality into an LLM.
Extra broadly, we count on many advances from the LLM ecosystem to switch naturally to this setting, and the boundary between an LLM and a recommender system could more and more blur. Our outcomes recommend it is a viable path towards less complicated recommender programs that align extra immediately with person satisfaction.
Acknowledgments
Contributors to this work (in alphabetical order): Abhishek Agrawal, Baolin Li, Casey Stella, Daneo Zhang, Dan Zheng, Donnie DeBoer, Fengdi Che, Fernando Amat Gil, Grace Huang, Inbar Naor, Ishita Verma, Jason Uh, Jimmy Patel, Justin Basilico, Lanxi Huang, Lingyi Liu, Liping Peng, Louis Wang, Michelle Kislak, Nathan Kallus, Nicolas Hortiguera, Paran Jain, Qusai Al-Rabadi, Rein Houthooft, Ryan Lee, Santino Ramos, Scarlet Chen, Shaojing Li, Sheallika Singh, Si Cheng, Wei Wang, and ZQ Zhang.
![]()
GenPage: In the direction of Finish-to-Finish Generative Homepage Development at Netflix was initially printed in Netflix TechBlog on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.