












By Vikram Srivastava and Marcelo Mayworm
Netflix has probably the most advanced information platforms within the cloud on which our information scientists and engineers run batch and streaming workloads. As our subscribers develop worldwide and Netflix enters the world of gaming, the variety of batch workflows and real-time information pipelines will increase quickly. The information platform is constructed on high of a number of distributed programs, and as a result of inherent nature of those programs, it’s inevitable that these workloads run into failures periodically. Troubleshooting these issues will not be a trivial activity and requires gathering logs and metrics from a number of completely different programs and analyzing them to establish the basis trigger. At our scale, even a tiny proportion of disrupted workloads can generate a considerable operational assist burden for the information platform crew when troubleshooting includes guide steps. And we are able to’t low cost the productiveness influence it causes on information platform customers.
It motivates us to be proactive in detecting and dealing with failed workloads in our manufacturing atmosphere, avoiding interruptions that would decelerate our groups. Now we have been engaged on an auto-diagnosis and remediation system known as Pensive within the information platform to deal with these considerations. With the purpose of troubleshooting failing and gradual workloads and remediating them with out human intervention wherever potential. As our platform continues to develop and completely different situations and points can disrupt the workloads, Pensive needs to be proactive in detecting broad issues on the platform degree in real-time and diagnosing the influence throughout the workloads.
Pensive infrastructure includes two separate programs to assist batch and streaming workloads. This weblog will discover these two programs and the way they carry out auto-diagnosis and remediation throughout our Large Information Platform and Actual-time infrastructure.
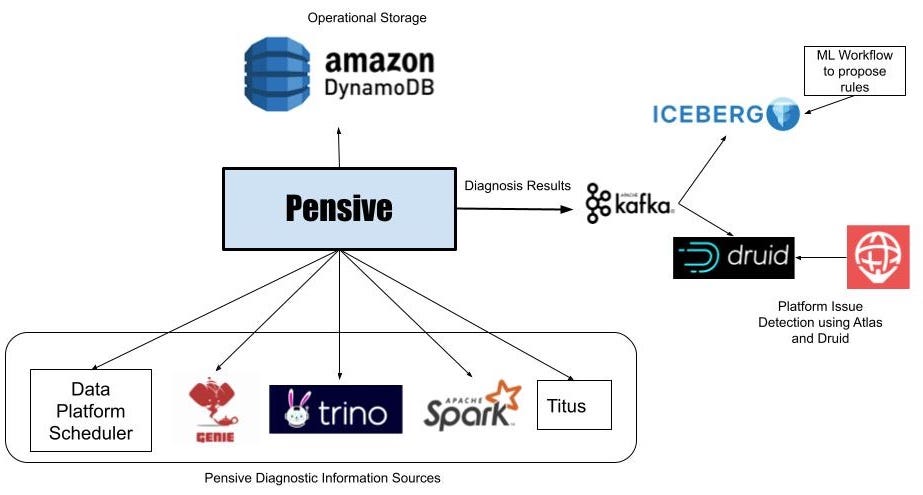
Batch workflows within the information platform run utilizing a Scheduler service that launches containers on the Netflix container administration platform known as Titus to run workflow steps. These steps launch jobs on clusters working Apache Spark and TrinoDb by way of Genie. If a workflow step fails, Scheduler asks Pensive to diagnose the step’s error. Pensive collects logs for the failed jobs launched by the step from the related information platform parts after which extracts the stack traces. Pensive depends on an everyday expression primarily based guidelines engine that has been curated over time. The foundations encode details about whether or not an error is because of a platform challenge or a person bug and whether or not the error is transient or not. If an everyday expression from one of many guidelines matches, then Pensive returns details about that error to the Scheduler. If the error is transient, Scheduler will retry that step with exponential backoff a number of extra instances.
Probably the most important a part of Pensive is the algorithm used to categorise an error. We have to evolve them because the platform evolves to make sure that the share of errors that Pensive can not classify stays low. Initially, the principles have been added on an ad-hoc foundation as requests got here in from platform part house owners and customers. Now we have now moved to a extra systematic method the place unknown errors are fed right into a Machine Studying course of that performs clustering to suggest new common expressions for generally occurring errors. We take the proposals to platform part house owners to then give you the classification of the error supply and whether or not it’s of transitory nature. Sooner or later, we want to automate this course of.
Detection of Platform-wide Points
Pensive does error classification on particular person workflow step failures, however by doing real-time analytics on the errors detected by Pensive utilizing Apache Kafka and Apache Druid, we are able to shortly establish platform points affecting many workflows. As soon as the person diagnoses get saved in a Druid desk, our monitoring and alerting system known as Atlas does aggregations each minute and sends out alerts if there’s a sudden improve within the variety of failures as a result of platform errors. This has led to a dramatic discount within the time it takes to detect points in {hardware} or bugs in just lately rolled out information platform software program.
Apache Flink powers real-time stream processing jobs within the Netflix information platform. And a lot of the Flink jobs run underneath a managed platform known as Keystone, which abstracts out the underlying Flink job particulars and permits customers to devour information from Apache Kafka streams and publish them to completely different information shops like Elasticsearch and Apache Iceberg on AWS S3.
For the reason that information platform manages keystone pipelines, customers count on platform points to be detected and remediated by the Keystone crew with none involvement from their finish. Moreover, information in Kafka streams have a finite retention interval, which provides time stress for resolving the problems to keep away from information loss.
For each Flink job working as a part of a Keystone pipeline, we monitor the metric indicating how far the Flink client lags behind the Kafka producer. If it crosses a threshold, Atlas sends a notification to Streaming Pensive.
Like its batch counterpart, Streaming Pensive additionally has a guidelines engine to diagnose errors. Nonetheless, along with logs, Streaming Pensive additionally has guidelines for checking numerous metric values for a number of parts within the Keystone pipeline. The problem might happen within the supply Kafka stream, the primary Flink job, or the sinks to which the Flink job is writing information. Streaming Pensive diagnoses it and tries to remediate the difficulty robotically when it occurs. Some examples the place we’re in a position to auto-remediate are:
- If Streaming Pensive finds that a number of Flink Process Managers are going out of reminiscence, it will probably redeploy the Flink cluster with extra Process Managers.
- If Streaming Pensive finds that there’s an sudden improve within the fee of incoming messages on the supply Kafka cluster, it will probably improve the subject retention dimension and interval in order that we don’t lose any information whereas the patron is lagging. If the spike goes away after a while, Streaming Pensive can revert the retention modifications. In any other case, it should web page the job proprietor to research if there’s a bug inflicting the elevated fee or if the shoppers should be reconfigured to deal with the upper fee.
Regardless that we have now a excessive success fee, there are nonetheless events the place automation will not be potential. If guide intervention is required, Streaming Pensive will web page the related part crew to take well timed motion to resolve the difficulty.
Pensive has had a major influence on the operability of the Netflix information platform. And helped engineering groups decrease the burden of operations work, releasing them to deal with extra important and difficult issues. However our job is nowhere close to achieved. Now we have a protracted roadmap forward of us. A few of the options and expansions we have now deliberate are:
- Batch Pensive is presently diagnosing failed jobs solely, and we wish to improve the scope into optimization to find out why jobs have develop into gradual.
- Auto-configure batch workflows in order that they end efficiently or develop into sooner and use fewer sources when potential. One instance the place it will probably dramatically assistance is Spark jobs, the place reminiscence tuning is a major problem.
- Develop Pensive with Machine Studying classifiers.
- The streaming platform just lately added Information Mesh, and we have to develop Streaming Pensive to cowl that.
This work couldn’t have been accomplished with out the assistance of the Large Information Compute and the Actual-time Information Infrastructure groups throughout the Netflix information platform. They’ve been nice companions for us as we work on bettering the Pensive infrastructure.







