














Netflix is utilized by 222 million members and runs on over 1700 gadget sorts starting from state-of-the-art good TVs to low-cost cellular units.
At Netflix we’re pleased with our reliability and we wish to maintain it that means. To that finish, it’s vital that we forestall vital efficiency regressions from reaching the manufacturing app. Sluggish scrolling or late rendering is irritating and triggers unintended navigations. Uneven playback makes watching a present much less pleasant. Any efficiency regression that makes it right into a product launch will degrade person expertise, so the problem is to detect and repair such regressions earlier than they ship.
This publish describes how the Netflix TVUI crew applied a strong technique to shortly and simply detect efficiency anomalies earlier than they’re launched — and infrequently earlier than they’re even dedicated to the codebase.
Technically, “efficiency” metrics are these referring to the responsiveness or latency of the app, together with begin up time.
However TV units additionally are typically extra reminiscence constrained than different units, and as such are extra liable to crash throughout a reminiscence spike — so for Netflix TV we really care about reminiscence a minimum of as a lot as efficiency, perhaps extra so.
At Netflix the time period “efficiency” often encompasses each efficiency metrics (within the strict that means) and reminiscence metrics, and that’s how we’re utilizing the time period right here.
It’s more durable to purpose concerning the efficiency profile of pre-production code since we will’t collect real-time metrics for code that hasn’t but shipped. We do reduce a canary launch upfront of cargo which is dogfooded by Netflix workers and topic to the identical metrics assortment because the manufacturing launch. Whereas the canary launch is a helpful dry-run for pending shipments, it typically misses regressions as a result of the canary person base is a fraction of the manufacturing launch. And within the occasion that regressions are detected within the canary, it nonetheless necessitates an usually messy and time consuming revert or patch.
By operating efficiency checks towards each commit (pre- and post-merge), we will detect doubtlessly regressive commits earlier. The earlier we detect such commits the less subsequent builds are affected and the simpler it’s to revert. Ideally we catch regressions earlier than they even attain the primary department.
The aim of our TVUI Efficiency Exams is to collect reminiscence and responsiveness metrics whereas simulating the complete vary of member interactions with Netflix TV.
There are roughly 50 efficiency checks, each designed to breed a facet of member engagement. The aim is to maintain every take a look at transient and centered on a particular, remoted piece of performance (startup, profile switching, scrolling by titles, choosing an episode, playback and so forth.), whereas the take a look at suite as a complete ought to cowl your entire member expertise with minimal duplication. On this means we will run a number of checks in parallel and the absence of lengthy pole checks retains the general take a look at time manageable and permits for repeat take a look at runs. Each take a look at runs on a mixture of units (bodily and digital) and platform variations (SDKs). We’ll refer to every distinctive take a look at/gadget/SDK mixture as a take a look at variation.
We run the complete efficiency suite twice per Pull Request (PR):
- when the PR is first submitted
- when the PR is merged to the vacation spot department
Measurement
Every efficiency take a look at tracks both reminiscence or responsiveness. Each of those metrics will fluctuate over the course of a take a look at, so we publish metric values at common intervals all through the take a look at. To check take a look at runs we’d like a way to consolidate this vary of noticed values right into a single worth.
We made the next choices:
Reminiscence Exams: use the utmost reminiscence worth noticed in the course of the take a look at run (as a result of that’s the worth that determines whether or not a tool may crash).
Responsiveness Exams : use the median worth noticed in the course of the take a look at run (primarily based on the belief that perceived slowness is influenced by all responses, not simply the worst response).
When Netflix is operating in manufacturing, we seize real-time efficiency information which makes it comparatively straightforward to make assertions concerning the app’s efficiency. It’s a lot more durable to evaluate the efficiency of pre-production code (modifications merged to the primary department however not but launched) and more durable nonetheless to get a efficiency sign for unmerged code in a PR. Efficiency take a look at metrics are inferior to real-time utilization metrics for a number of causes:
- Knowledge quantity: Within the Netflix app, the identical steps are repeated billions of occasions, however developer velocity and useful resource constraints dictate that efficiency checks can solely run a handful of occasions per construct.
- Simulation: Regardless of how rigorous or artistic our testing course of is, we will solely ever approximate the expertise of actual life customers, by no means replicate it. Actual customers repeatedly use Netflix for hours at a time, and each person has completely different preferences and habits.
- Noise: Ideally a given codebase operating any given take a look at variation will all the time return similar outcomes. In actuality that simply by no means occurs: no two gadget CPUs are similar, rubbish assortment shouldn’t be solely predictable, API request quantity and backend exercise is variable — so are energy ranges and community bandwidth. For each take a look at there shall be background noise that we have to in some way filter from our evaluation.
For our first try at efficiency validation we assigned most acceptable threshold values for reminiscence metrics. There was a sound rationale behind this method — when a TV runs Netflix there’s a arduous restrict for reminiscence footprint past which Netflix has the potential to crash.
There have been a number of points with the static thresholds method:
- Customized preparation work per take a look at: Since every take a look at variation has a novel reminiscence profile, the suitable static threshold needed to be researched and assigned on a case-by-case foundation. This was troublesome and time consuming, so we solely assigned thresholds to about 30% of take a look at variations.
- Lack of context: As a validation method, static thresholds proved to be considerably arbitrary. Think about a commit that will increase reminiscence utilization by 10% however to a stage which is just under the edge. The following commit is likely to be a README change (zero reminiscence influence) however resulting from regular variations in gadget background noise, the metric may improve by simply sufficient to breach the edge.
- Background variance shouldn’t be filtered: As soon as the codebase is bumping towards the reminiscence threshold, background gadget noise turns into the principal issue figuring out which facet of the edge line the take a look at end result falls.
- Put up-alert changes: We discovered ourselves repeatedly rising the thresholds to maneuver them away from background noise
It grew to become obvious we wanted a method for efficiency validation that:
- Removes failure bias by giving equal weight to all take a look at runs, no matter outcomes
- Doesn’t deal with efficiency information factors in isolation, however as an alternative assesses the efficiency influence of a construct in relation to earlier builds.
- May be robotically utilized to each take a look at with out the necessity for pre-hoc analysis, information entry or ongoing guide intervention
- Could possibly be equally utilized to check information of any kind: reminiscence, responsiveness, or every other non-boolean take a look at information
- Minimizes the influence of background noise by prioritizing variance over absolute values
- Improves perception by analyzing information factors each on the time of creation and retroactively
We settled on a two-pronged method:
- Anomaly Detection instantly calls out potential efficiency regressions by evaluating with current previous information
- Changepoint Detection identifies extra delicate efficiency inflections by analyzing previous and future information clusters
Anomaly Detection
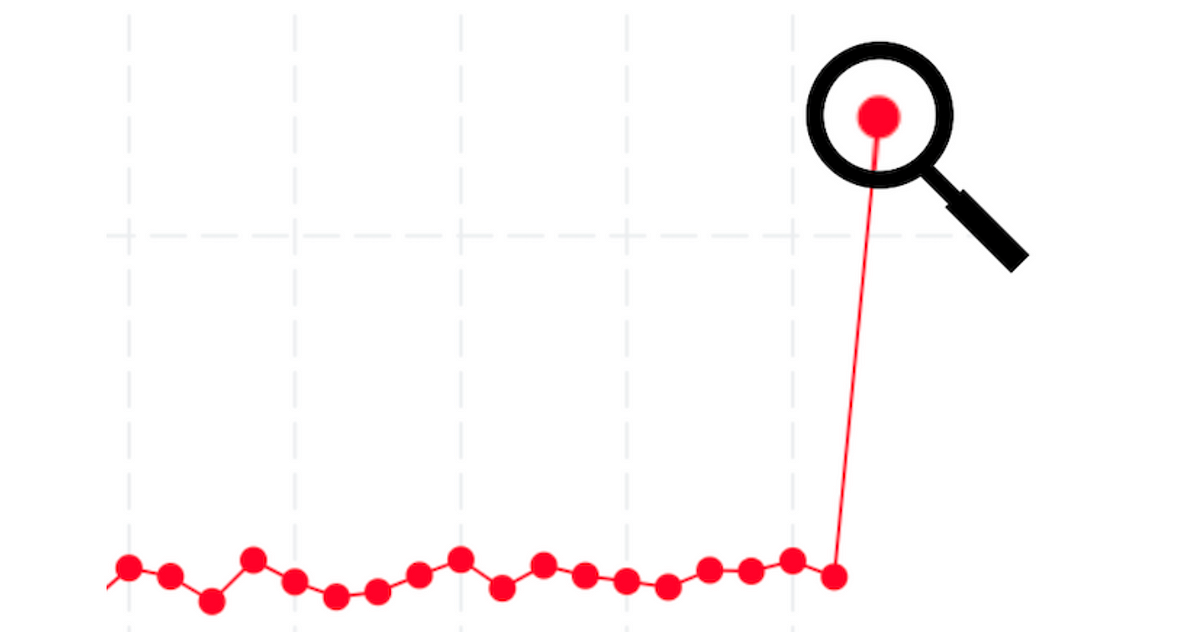
We outline an anomaly as any metric information level that’s greater than n normal deviations above the current imply, the place current imply and normal deviation are derived from the earlier m take a look at runs. For Netflix TV efficiency checks we at present set n to 4 and m to 40 however these values will be tweaked to maximise sign to noise ratio. When an anomaly is detected the take a look at standing is ready to failed and an alert is generated.
Anomaly detection works as a result of thresholds are dynamic and derived from current information. If the information displays numerous background variance then the anomaly threshold will improve to account for the additional noise.
Changepoints
Changepoints are information factors on the boundary of two distinct information distribution patterns. We use a method known as e-divisive to investigate the 100 most up-to-date take a look at runs, utilizing a Python implementation primarily based on this implementation.
Since we’re solely concerned with efficiency regressions, we ignore changepoints that development decrease. When a changepoint is detected for a take a look at, we don’t fail the take a look at or generate an alert (we contemplate changepoints to be warnings of surprising patterns, not full blown error assertions).
As you possibly can see, changepoints are a extra delicate sign. They don’t essentially point out a regression however they counsel builds that had an influence on subsequent information distribution.
Builds that generate changepoints throughout a number of checks, warrant additional investigation earlier than they are often included within the launch candidate.
Changepoints give us extra confidence in regression detection as a result of they disregard false positives comparable to one time information spikes. As a result of changepoint detection requires after-the-fact information, they’re greatest suited to figuring out doubtlessly regressive code that’s already in the primary department however has not but been shipped.
Runs per Check
To handle failure bias, we determined to run all checks 3 occasions, whatever the end result. We selected 3 iterations to supply sufficient information to remove most gadget noise (checks are allotted to units randomly) with out making a productiveness bottleneck.
Summarizing throughout Check Runs
Subsequent we wanted to determine on a strategy to compress the outcomes of every batch of three runs right into a single worth. The aim was to disregard outlier outcomes brought on by erratic gadget conduct.
Initially we took the typical of these three runs, however that led to an extra of false positives as a result of probably the most irregular take a look at runs exerted an excessive amount of affect on the end result. Switching to the median eradicated a few of these false positives however we had been nonetheless getting an unacceptable variety of extra alerts (as a result of during times of excessive gadget noise we might sometimes see outlier outcomes two occasions out of three). Lastly, since we seen that outlier outcomes tended to be larger than regular — hardly ever decrease — we settled on utilizing the minimal worth throughout the three runs and this proved to be the simplest at eliminating exterior noise.
After switching our efficiency validation to make use of anomaly and changepoint detection we seen a number of enhancements.
a) We’re alerted for potential efficiency regressions far much less usually, and once we do get alerted it’s more likely to point a real regression. Our workload is additional lowered by now not having to manually increment static efficiency thresholds after every false optimistic.
The next desk represents the alert abstract for 2 distinct months final yr. In March 2021 we nonetheless used static thresholds for regression alerts. By October 2021 we had switched utilizing anomaly detection for regression alerts. Alerts which had been true regressions is the variety of alerted commits for which the suspected regression turned out to be each vital and protracted.
Be aware that for the reason that March checks solely validated when a threshold was manually set, the full variety of validating take a look at runs in October was a lot better, and but we nonetheless bought solely 10% of the alerts.
b) We’re not alerted for subsequent innocuous builds that inherit regressive commits from previous builds. (Utilizing the static threshold method, all subsequent builds had been alerted till the regressive construct was reverted.) It is because regressive builds improve each imply and normal deviation and thus put subsequent non-regressing builds comfortably beneath the alert threshold.
c) Efficiency checks towards PRs, which had been virtually consistently pink (as a result of the chance of a minimum of one static threshold being breached was all the time excessive), are actually largely inexperienced. When the efficiency checks are pink we now have a a lot larger confidence that there’s a real efficiency regression.
d) Displaying the anomaly and changepoint rely per construct gives a visible snapshot that shortly highlights doubtlessly problematic builds.
Additional Work
There are nonetheless a number of issues we’d like to enhance
- Make it simpler to find out if regressions had been resulting from exterior brokers: Typically it seems the detected regression, although actual, was not a results of the dedicated code however resulting from an exterior issue comparable to an improve to certainly one of our platform dependencies, or a function flag that bought switched on. It could be useful to summarize exterior modifications in our alert summaries.
- Issue out resolved regressions when figuring out baselines for validation:
When producing current imply and normal deviation values, we may enhance regression detection by filtering out information from erstwhile regressions which have since been mounted. - Enhance Developer Velocity: We will additional scale back complete take a look at time by eradicating pointless iterations inside checks, including extra units to make sure availability, and de-emphasizing testing for these elements of the app the place efficiency is much less prone to be crucial. We will additionally pre-build app bundles (a minimum of partially) in order that the take a look at suite shouldn’t be delayed by ready for recent builds.
- Extra carefully mirror metrics gathered by the manufacturing app: Within the deployed Netflix TV app we acquire extra metrics comparable to TTR (time to render) and empty field price (how ceaselessly titles within the viewport are lacking pictures). Whereas take a look at metrics and metrics collected throughout actual use don’t lend themselves to direct comparability, measuring the relative change in metrics in pre-production builds will help us to anticipate regressions in manufacturing.
Wider Adoption and New Use Instances
At this level Anomaly and Changepoint detection is utilized to each commit within the TVUI repo, and is within the strategy of being deployed for commits to the TV Participant repo (the layer that manages playback operations). Different Netflix groups (exterior of the TV platform) have additionally expressed curiosity in these strategies and the final word aim is to standardize regression detection throughout Netflix.
Anomaly and changepoint detection are solely framework unbiased — the one required inputs are a present worth and an array of current values to check it to. As such, their utility extends far past efficiency checks. For instance, we’re contemplating utilizing these strategies to observe the reliability of non-performance-based take a look at suites — on this case the metric of curiosity is the % of checks that ran to completion.
Sooner or later we plan to decouple anomaly and changepoint logic from our take a look at infrastructure and supply it as a standalone open-source library.
Through the use of strategies that assess the efficiency influence of a construct in relation to the efficiency traits (magnitude, variance, development) of adjoining builds, we will extra confidently distinguish real regressions from metrics which are elevated for different causes (e.g. inherited code, regressions in earlier builds or one-off information spikes resulting from take a look at irregularities). We additionally spend much less time chasing false negatives and now not have to manually assign a threshold to every end result — the information itself now units the thresholds dynamically.
This improved effectivity and better confidence stage helps us to shortly establish and repair regressions earlier than they attain our members.
The anomaly and changepoint strategies mentioned right here can be utilized to establish regressions (or progressions), surprising values or inflection factors in any chronologically sequenced, quantitative information. Their utility extends properly past efficiency evaluation. For instance they might be used to establish inflection factors in system reliability, buyer satisfaction, product utilization, obtain quantity or income.
We encourage you to attempt these strategies by yourself information. We’d like to study extra about their success (or in any other case) in different contexts!







