












by Aryan Mehra
with Farnaz Karimdady Sharifabad, Prasanna Vijayanathan, Chaïna Wade, Vishal Sharma and Mike Schassberger


The aim of this text is to present insights into analyzing and predicting “out of reminiscence” or OOM kills on the Netflix App. Not like sturdy compute units, TVs and set high bins normally have stronger reminiscence constraints. Extra importantly, the low useful resource availability or “out of reminiscence” state of affairs is without doubt one of the frequent causes for crashes/kills. We at Netflix, as a streaming service working on thousands and thousands of units, have an amazing quantity of information about system capabilities/traits and runtime knowledge in our large knowledge platform. With giant knowledge, comes the chance to leverage the info for predictive and classification based mostly evaluation. Particularly, if we’re capable of predict or analyze the Out of Reminiscence kills, we are able to take system particular actions to pre-emptively decrease the efficiency in favor of not crashing — aiming to present the person the final word Netflix Expertise inside the “efficiency vs pre-emptive motion” tradeoff limitations. A significant benefit of prediction and taking pre-emptive motion, is the truth that we are able to take actions to raised the person expertise.
That is accomplished by first elaborating on the dataset curation stage — specifically focussing on system capabilities and OOM kill associated reminiscence readings. We additionally spotlight steps and tips for exploratory evaluation and prediction to grasp Out of Reminiscence kills on a pattern set of units. Since reminiscence administration just isn’t one thing one normally associates with classification issues, this weblog focuses on formulating the issue as an ML drawback and the info engineering that goes together with it. We additionally discover graphical evaluation of the labeled dataset and recommend some function engineering and accuracy measures for future exploration.
Not like different Machine Studying duties, OOM kill prediction is difficult as a result of the dataset will likely be polled from completely different sources — system traits come from our on-field data and runtime reminiscence knowledge comes from real-time person knowledge pushed to our servers.
Secondly, and extra importantly, the sheer quantity of the runtime knowledge is quite a bit. A number of units working Netflix will log reminiscence utilization at mounted intervals. For the reason that Netflix App doesn’t get killed fairly often (luckily!), this implies most of those entries signify regular/supreme/as anticipated runtime states. The dataset will thus be very biased/skewed. We are going to quickly see how we really label which entries are faulty and which aren’t.

The schema determine above describes the 2 elements of the dataset — system capabilities/traits and runtime reminiscence knowledge. When joined collectively based mostly on attributes that may uniquely match the reminiscence entry with its system’s capabilities. These attributes could also be completely different for various streaming companies — for us at Netflix, this can be a mixture of the system sort, app session ID and software program growth equipment model (SDK model). We now discover every of those elements individually, whereas highlighting the nuances of the info pipeline and pre-processing.
System Capabilities
All of the system capabilities could not reside in a single supply desk — requiring a number of if not a number of joins to assemble the info. Whereas creating the system functionality desk, we determined to main index it by a composite key of (system sort ID, SDK model). So given these two attributes, Netflix can uniquely establish a number of of the system capabilities. Some nuances whereas creating this dataset come from the on-field area data of our engineers. Some options (for example) embrace System Kind ID, SDK Model, Buffer Sizes, Cache Capacities, UI decision, Chipset Producer and Model.
Main Milestones in Information Engineering for System Traits
Structuring the info in an ML-consumable format: The system functionality knowledge wanted for the prediction was distributed in over three completely different schemas throughout the Massive Information Platform. Becoming a member of them collectively and constructing a single indexable schema that may straight develop into part of a much bigger knowledge pipeline is an enormous milestone.
Coping with ambiguities and lacking knowledge: Generally the entries in BDP are contaminated with testing entries and NULL values, together with ambiguous values that don’t have any which means or simply merely contradictory values resulting from unreal take a look at environments. We cope with all of this by a easy majority voting (statistical mode) on the view that’s listed by the system sort ID and SDK model from the person question. We thus confirm the speculation that precise system traits are at all times in majority within the knowledge lake.
Incorporating On-site and discipline data of units and engineers: That is in all probability the one most necessary achievement of the duty as a result of among the options talked about above (and among the ones redacted) concerned engineering the options manually. Instance: Lacking values or NULL values may imply the absence of a flag or function in some attribute, whereas it’d require additional duties in others. So if we’ve got a lacking worth for a function flag, that may imply “False”, whereas a lacking worth in some buffer dimension function may imply that we want subqueries to fetch and fill the lacking knowledge.
Runtime Reminiscence, OOM Kill Information and floor fact labeling
Runtime knowledge is at all times growing and continuously evolving. The tables and views we use are refreshed each 24 hours and becoming a member of between any two such tables will result in large compute and time sources. As a way to curate this a part of the dataset, we advise some suggestions given under (written from the standpoint of SparkSQL-like distributed question processors):
- Filtering the entries (circumstances) earlier than JOIN, and for this goal utilizing WHERE and LEFT JOIN clauses rigorously. Situations that get rid of entries after the be a part of operation are way more costly than when elimination occurs earlier than the be a part of. It additionally prevents the system working out of reminiscence throughout execution of the question.
- Limiting Testing and Evaluation to in the future and system at a time. It’s at all times good to choose a single excessive frequency day like New Years, or Memorial day, and many others. to extend frequency counts and get normalized distributions throughout numerous options.
- Placing a stability between driver and executor reminiscence configurations in SparkSQL-like programs. Too excessive allocations could fail and limit system processes. Too low reminiscence allocations could fail on the time of an area acquire or when the motive force tries to build up the outcomes.
Labeling the info — Floor Reality

An necessary facet of the dataset is to grasp what options will likely be out there to us at inference time. Thus reminiscence knowledge (that comprises the navigational stage and reminiscence studying) may be labeled utilizing the OOM kill knowledge, however the latter can’t be mirrored within the enter options. One of the simplest ways to do that is to make use of a sliding window method the place we label the reminiscence readings of the classes in a set window earlier than the OOM kill as faulty, and the remainder of the entries as non-erroneous. As a way to make the labeling extra granular, and produce extra variation in a binary classification mannequin, we suggest a graded window method as defined by the picture under. Mainly, it assigns increased ranges to reminiscence readings nearer to the OOM kill, making it a multi-class classification drawback. Degree 4 is probably the most close to to the OOM kill (vary of two minutes), whereas Degree 0 is past 5 minutes of any OOM kill forward of it. We notice right here that the system and session of the OOM kill occasion and the reminiscence studying must match for the sanity of the labeling. Later the confusion matrix and mannequin’s outcomes can later be diminished to binary if want be.

The dataset now consists of a number of entries — every of which has sure runtime options (navigational stage and reminiscence studying in our case) and system traits (a mixture of over 15 options which may be numerical, boolean or categorical). The output variable is the graded or ungraded classification variable which is labeled in accordance with the part above — based totally on the nearness of the reminiscence studying stamp to the OOM kill. Now we are able to use any multi-class classification algorithm — ANNs, XGBoost, AdaBoost, ElasticNet with softmax and many others. Thus we’ve got efficiently formulated the issue of OOM kill prediction for a tool streaming Netflix.
With out diving very deep into the precise units and outcomes of the classification, we now present some examples of how we might use the structured knowledge for some preliminary evaluation and make observations. We achieve this by simply trying on the peak of OOM kills in a distribution over the reminiscence readings inside 5 minutes previous to the kill.

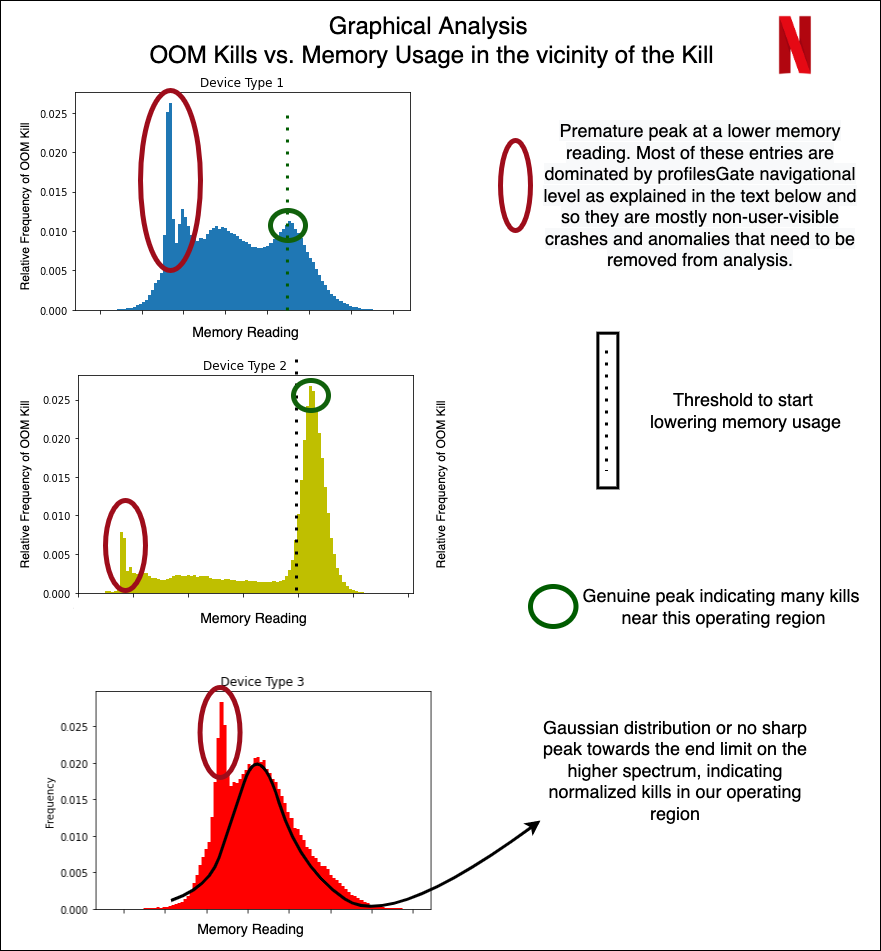
From the graph above, we present how even with out doing any modeling, the structured knowledge can provide us immense data concerning the reminiscence area. For instance, the early peaks (marked in crimson) are principally crashes not seen to customers, however have been marked erroneously as user-facing crashes. The peaks marked in inexperienced are actual user-facing crashes. System 2 is an instance of a pointy peak in the direction of the upper reminiscence vary, with a decline that’s sharp and nearly no entries after the height ends. Therefore, for System 1 and a couple of, the duty of OOM prediction is comparatively simpler, after which we are able to begin taking pre-emptive motion to decrease our reminiscence utilization. In case of System 3, we’ve got a normalized gaussian like distribution — indicating that the OOM kills happen throughout, with the decline not being very sharp, and the crashes occur throughout in an roughly normalized trend.
We depart the reader with some concepts to engineer extra options and accuracy measures particular to the reminiscence utilization context in a streaming surroundings for a tool.
- We might manually engineer options on reminiscence to make the most of the time-series nature of the reminiscence worth when aggregated over a person’s session. Recommendations embrace a working imply of the final 3 values, or a distinction of the present entry and working exponential common. The evaluation of the expansion of reminiscence by the person might give insights into whether or not the kill was attributable to in-app streaming demand, or resulting from exterior components.
- One other function might be the time spent in numerous navigational ranges. Internally, the app caches a number of pre-fetched knowledge, photographs, descriptions and many others, and the time spent within the stage might point out whether or not or not these caches are cleared.
- When deciding on accuracy measures for the issue, it is very important analyze the excellence between false positives and false negatives. The dataset (luckily for Netflix!) will likely be extremely biased — for example, over 99.1% entries are non-kill associated. Basically, false negatives (not predicting the kill when really the app is killed) are extra detrimental than false positives (predicting a kill though the app might have survived). It is because for the reason that kill occurs not often (0.9% on this instance), even when we find yourself decreasing reminiscence and efficiency 2% of the time and catch nearly all of the 0.9% OOM kills, we can have eradicated roughly. all OOM kills with the tradeoff of decreasing the efficiency/clearing the cache an additional 1.1% of the time (False Positives).
This submit has focussed on throwing gentle on dataset curation and engineering when coping with reminiscence and low useful resource crashes for streaming companies on system. We additionally cowl the excellence between non-changing attributes and runtime attributes and methods to affix them to make one cohesive dataset for OOM kill prediction. We lined labeling methods that concerned graded window based mostly approaches and explored some graphical evaluation on the structured dataset. Lastly, we ended with some future instructions and potentialities for function engineering and accuracy measurements within the reminiscence context.
Keep tuned for additional posts on reminiscence administration and the usage of ML modeling to cope with systemic and low latency knowledge collected on the system stage. We are going to attempt to quickly submit outcomes of our fashions on the dataset that we’ve got created.
Acknowledgements
I wish to thank the members of varied groups — Accomplice Engineering, TVUI group, Streaming Information Crew, Massive Information Platform Crew, System Ecosystem Crew and Information Science Crew, for all their help.







