












by Ehtsham Elahi
with James McInerney, Nathan Kallus, Dario Garcia Garcia and Justin Basilico
This writeup is about utilizing reinforcement studying to assemble an optimum listing of suggestions when the person has a finite time finances to decide from the listing of suggestions. Working inside the time finances introduces an additional useful resource constraint for the recommender system. It’s much like many different resolution issues (for e.g. in economics and operations analysis) the place the entity making the choice has to seek out tradeoffs within the face of finite sources and a number of (probably conflicting) goals. Though time is crucial and finite useful resource, we predict that it’s an typically ignored side of advice issues.
Along with relevance of the suggestions, time finances additionally determines whether or not customers will settle for a suggestion or abandon their search. Think about the state of affairs {that a} person involves the Netflix homepage on the lookout for one thing to observe. The Netflix homepage supplies a lot of suggestions and the person has to judge them to decide on what to play. The analysis course of could embody making an attempt to acknowledge the present from its field artwork, watching trailers, studying its synopsis or in some circumstances studying evaluations for the present on some exterior web site. This analysis course of incurs a value that may be measured in items of time. Totally different reveals would require completely different quantities of analysis time. If it’s a well-liked present like Stranger Issues then the person could already concentrate on it and should incur little or no price earlier than selecting to play it. Given the restricted time finances, the advice mannequin ought to assemble a slate of suggestions by contemplating each the relevance of the gadgets to the person and their analysis price. Balancing each of those points might be troublesome as a extremely related merchandise could have a a lot increased analysis price and it might not match inside the person’s time finances. Having a profitable slate due to this fact will depend on the person’s time finances, relevance of every merchandise in addition to their analysis price. The objective for the advice algorithm due to this fact is to assemble slates which have a better probability of engagement from the person with a finite time finances. It is very important level out that the person’s time finances, like their preferences, might not be immediately observable and the recommender system could need to be taught that along with the person’s latent preferences.
We’re eager about settings the place the person is offered with a slate of suggestions. Many recommender methods depend on a bandit model strategy to slate building. A bandit recommender system developing a slate of Ok gadgets could appear like the next:

To insert a component at slot okay within the slate, the merchandise scorer scores the entire accessible N gadgets and should make use of the slate constructed to this point (slate above) as extra context. The scores are then handed by a sampler (e.g. Epsilon-Grasping) to pick an merchandise from the accessible gadgets. The merchandise scorer and the sampling step are the principle parts of the recommender system.
Let’s make the issue of finances constrained suggestions extra concrete by contemplating the next (simplified) setting. The recommender system presents a one dimensional slate (an inventory) of Ok gadgets and the person examines the slate sequentially from prime to backside.

The person has a time finances which is a few optimistic actual valued quantity. Let’s assume that every merchandise has two options, relevance (a scalar, increased worth of relevance signifies that the merchandise is extra related) and price (measured in a unit of time). Evaluating every suggestion consumes from the person’s time finances and the person can not browse the slate as soon as the time finances has exhausted. For every merchandise examined, the person makes a probabilistic resolution to eat the advice by flipping a coin with chance of success proportional to the relevance of the video. Since we need to mannequin the person’s chance of consumption utilizing the relevance function, it’s useful to consider relevance as a chance immediately (between 0 and 1). Clearly the chance to decide on one thing from the slate of suggestions relies not solely on the relevance of the gadgets but additionally on the variety of gadgets the person is ready to study. A suggestion system making an attempt to maximise the person’s engagement with the slate must pack in as many related gadgets as potential inside the person finances, by making a trade-off between relevance and price.
Let’s take a look at it from one other perspective. Think about the next definitions for the slate suggestion downside described above


Clearly the abandonment chance is small if the gadgets are extremely related (excessive relevance) or the listing is lengthy (because the abandonment chance is a product of chances). The abandonment possibility is typically known as the null alternative/arm in bandit literature.
This downside has clear connections with the 0/1 Knapsack downside in theoretical laptop science. The objective is to seek out the subset of things with the very best complete utility such that the entire price of the subset just isn’t larger than the person finances. If β_i and c_i are the utility and price of the i-th merchandise and u is the person finances, then the finances constrained suggestions might be formulated as

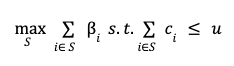
There may be an extra requirement that optimum subset S be sorted in descending order in response to the relevance of things within the subset.
The 0/1 Knapsack downside is a nicely studied downside and is understood to be NP-Full. There are a lot of approximate options to the 0/1 Knapsack downside. On this writeup, we suggest to mannequin the finances constrained suggestion downside as a Markov Resolution course of and use algorithms from reinforcement studying (RL) to discover a answer. It is going to turn out to be clear that the RL based mostly answer to finances constrained suggestion issues matches nicely inside the recommender system structure for slate building. To start, we first mannequin the finances constrained suggestion downside as a Markov Resolution Course of.
In a Markov resolution course of, the important thing element is the state evolution of the atmosphere as a perform of the present state and the motion taken by the agent. Within the MDP formulation of this downside, the agent is the recommender system and the atmosphere is the person interacting with the recommender system. The agent constructs a slate of Ok gadgets by repeatedly deciding on actions it deems applicable at every slot within the slate. The state of the atmosphere/person is characterised by the accessible time finances and the gadgets examined within the slate at a specific step within the slate shopping course of. Particularly, the next desk defines the Markov Resolution Course of for the finances constrained suggestion downside,


In actual world recommender methods, the person finances might not be observable. This downside might be solved by computing an estimate of the person finances from historic knowledge (e.g. how lengthy the person scrolled earlier than abandoning within the historic knowledge logs). On this writeup, we assume that the recommender system/agent has entry to the person finances for sake of simplicity.
The slate technology process above is an episodic process i-e the recommender agent is tasked with selecting Ok gadgets within the slate. The person supplies suggestions by selecting one or zero gadgets from the slate. This may be considered as a binary reward r per merchandise within the slate. Let π be the recommender coverage producing the slate and γ be the reward low cost issue, we are able to then outline the discounted return for every state, motion pair as,

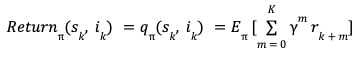
The reinforcement studying algorithm we make use of relies on estimating this return utilizing a mannequin. Particularly, we use Temporal Distinction studying TD(0) to estimate the worth perform. Temporal distinction studying makes use of Bellman’s equation to outline the worth perform of present state and motion when it comes to worth perform of future state and motion.


Primarily based on this Bellman’s equation, a squared loss for TD-Studying is,


The loss perform might be minimized utilizing semi-gradient based mostly strategies. As soon as we have now a mannequin for q, we are able to use that because the merchandise scorer within the above slate recommender system structure. If the low cost issue γ =0, the return for every (state, motion) pair is just the fast person suggestions r. Subsequently q with γ = 0 corresponds to an merchandise scorer for a contextual bandit agent whereas for γ > 0, the recommender corresponds to a (worth perform based mostly) RL agent. Subsequently merely utilizing the mannequin for the worth perform because the merchandise scorer within the above system structure makes it very straightforward to make use of an RL based mostly answer.
As in different functions of RL, we discover simulations to be a useful software for learning this downside. Beneath we describe the generative course of for the simulation knowledge,


Word that, as an alternative of sampling the per-item Bernoulli, we are able to alternatively pattern as soon as from a categorical distribution with relative relevances for gadgets and a hard and fast weight for the null arm. The above generative course of for simulated knowledge will depend on many hyper-parameters (loc, scale and so forth.). Every setting of those hyper-parameters leads to a distinct simulated dataset and it’s straightforward to appreciate many simulated datasets in parallel. For the experiments under, we repair the hyper-parameters for the fee and relevance distributions and sweep over the preliminary person finances distribution’s location parameter. The hooked up pocket book comprises the precise settings of the hyper-parameters used for the simulations.
A slate suggestion algorithm generates slates after which the person mannequin is used to foretell the success/failure of every slate. Given the simulation knowledge, we are able to practice varied suggestion algorithms and evaluate their efficiency utilizing a easy metric as the typical variety of successes of the generated slates (known as play-rate under). Along with play-rate, we take a look at the effective-slate-size as nicely, which we outline to be the variety of gadgets within the slate that match the person’s time finances. As talked about earlier, one of many methods play-rate might be improved is by developing bigger efficient slates (with related gadgets of-course) so taking a look at this metric helps perceive the mechanism of the advice algorithms.
Given the pliability of working within the simulation setting, we are able to be taught to assemble optimum slates in an on-policy method. For this, we begin with some preliminary random mannequin for the worth perform, generate slates from it, get person suggestions (utilizing the person mannequin) after which replace the worth perform mannequin utilizing the suggestions and maintain repeating this loop till the worth perform mannequin converges. This is called the SARSA algorithm.
The next set of outcomes present how the realized recommender insurance policies behave when it comes to metric of success, play-rate for various settings of the person finances distributions’s location parameter and the low cost issue. Along with the play price, we additionally present the efficient slate dimension, common variety of gadgets that match inside the person finances. Whereas the play price modifications are statistically insignificant (the shaded areas are the 95% confidence intervals estimated utilizing bootstrapping simulations 100 instances), we see a transparent pattern within the improve within the efficient slate dimension (γ > 0) in comparison with the contextual bandit (γ= 0)


We are able to truly get a extra statistically delicate consequence by evaluating the results of the contextual bandit with an RL mannequin for every simulation setting (much like a paired comparability in paired t-test). Beneath we present the change in play price (delta play price) between any RL mannequin (proven with γ = 0.8 under for instance) and a contextual bandit (γ = 0). We evaluate the change on this metric for various person finances distributions. By performing this paired comparability, we see a statistically important raise in play price for small to medium finances person finances ranges. This makes intuitive sense as we might anticipate each approaches to work equally nicely when the person finances is just too massive (due to this fact the merchandise’s price is irrelevant) and the RL algorithm solely outperforms the contextual bandit when the person finances is proscribed and discovering the trade-off between relevance and price is necessary. The rise within the efficient slate dimension is much more dramatic. This consequence clearly reveals that the RL agent is performing higher by minimizing the abandonment chance by packing extra gadgets inside the person finances.

To date the outcomes have proven that within the finances constrained setting, reinforcement studying outperforms contextual bandit. These outcomes have been for the on-policy studying setting which could be very straightforward to simulate however troublesome to execute in sensible recommender settings. In a sensible recommender, we have now knowledge generated by a distinct coverage (referred to as a habits coverage) and we need to be taught a brand new and higher coverage from this knowledge (referred to as the goal coverage). That is referred to as the off-policy setting. Q-Studying is one well-known method that permits us to be taught optimum worth perform in an off-policy setting. The loss perform for Q-Studying is similar to the TD(0) loss besides that it makes use of Bellman’s optimality equation as an alternative

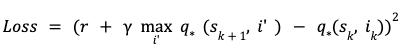
This loss can once more be minimized utilizing semi-gradient methods. We estimate the optimum worth perform utilizing Q-Studying and evaluate its efficiency with the optimum coverage realized utilizing the on-policy SARSA setup. For this, we generate slates utilizing Q-Studying based mostly optimum worth perform mannequin and evaluate the play-rate with the slates generated utilizing the optimum coverage realized with SARSA. Beneath is results of the paired comparability between SARSA and Q-Studying,

On this consequence, the change within the play-rate between on-policy and off-policy fashions is near zero (see the error bars crossing the zero-axis). This can be a favorable consequence as this reveals that Q-Studying leads to comparable efficiency because the on-policy algorithm. Nonetheless, the efficient slate dimension is kind of completely different between Q-Studying and SARSA. Q-Studying appears to be producing very massive efficient slate sizes with out a lot distinction within the play price. That is an intriguing consequence and wishes slightly extra investigation to totally uncover. We hope to spend extra time understanding this lead to future.
To conclude, on this writeup we offered the finances constrained suggestion downside and confirmed that with the intention to generate slates with increased probabilities of success, a recommender system has to steadiness each the relevance and price of things in order that extra of the slate matches inside the person’s time finances. We confirmed that the issue of finances constrained suggestion might be modeled as a Markov Resolution Course of and we are able to discover a answer to optimum slate building beneath finances constraints utilizing reinforcement studying based mostly strategies. We confirmed that the RL outperforms contextual bandits on this downside setting. Furthermore, we in contrast the efficiency of On-policy and Off-policy approaches and located the outcomes to be comparable when it comes to metrics of success.
Github repo







