











By Vadim Filanovsky and Harshad Sane
In considered one of our earlier blogposts, A Microscope on Microservices we outlined three broad domains of observability (or “ranges of magnification,” as we referred to them) — Fleet-wide, Microservice and Occasion. We described the instruments and strategies we use to realize perception inside every area. There’s, nevertheless, a category of issues that requires a good stronger degree of magnification going deeper down the stack to introspect CPU microarchitecture. On this blogpost we describe one such downside and the instruments we used to resolve it.
It began off as a routine migration. At Netflix, we periodically reevaluate our workloads to optimize utilization of obtainable capability. We determined to maneuver considered one of our Java microservices — let’s name it GS2 — to a bigger AWS occasion measurement, from m5.4xl (16 vCPUs) to m5.12xl (48 vCPUs). The workload of GS2 is computationally heavy the place CPU is the limiting useful resource. Whereas we perceive it’s just about not possible to attain a linear improve in throughput because the variety of vCPUs develop, a near-linear improve is attainable. Consolidating on the bigger situations reduces the amortized price of background duties, releasing up extra sources for serving requests and doubtlessly offsetting the sub-linear scaling. Thus, we anticipated to roughly triple throughput per occasion from this migration, as 12xl situations have 3 times the variety of vCPUs in comparison with 4xl situations. A fast canary check was freed from errors and confirmed decrease latency, which is anticipated on condition that our normal canary setup routes an equal quantity of site visitors to each the baseline operating on 4xl and the canary on 12xl. As GS2 depends on AWS EC2 Auto Scaling to target-track CPU utilization, we thought we simply needed to redeploy the service on the bigger occasion sort and watch for the ASG (Auto Scaling Group) to choose the CPU goal. Sadly, the preliminary outcomes had been removed from our expectations:
The primary graph above represents common per-node throughput overlaid with common CPU utilization, whereas the second graph reveals common request latency. We will see that as we reached roughly the identical CPU goal of 55%, the throughput elevated solely by ~25% on common, falling far wanting our desired objective. What’s worse, common latency degraded by greater than 50%, with each CPU and latency patterns changing into extra “uneven.” GS2 is a stateless service that receives site visitors by a taste of round-robin load balancer, so all nodes ought to obtain practically equal quantities of site visitors. Certainly, the RPS (Requests Per Second) knowledge reveals little or no variation in throughput between nodes:
However as we began trying on the breakdown of CPU and latency by node, a wierd sample emerged:
Though we confirmed pretty equal site visitors distribution between nodes, CPU and latency metrics surprisingly demonstrated a really completely different, bimodal distribution sample. There’s a “decrease band” of nodes exhibiting a lot decrease CPU and latency with hardly any variation; and there may be an “higher band” of nodes with considerably larger CPU/latency and vast variation. We seen solely ~12% of the nodes fall into the decrease band, a determine that was suspiciously constant over time. In each bands, efficiency traits stay constant for your complete uptime of the JVM on the node, i.e. nodes by no means jumped the bands. This was our start line for troubleshooting.
Our first (and reasonably apparent) step at fixing the issue was to match flame graphs for the “gradual” and “quick” nodes. Whereas flame graphs clearly mirrored the distinction in CPU utilization because the variety of collected samples, the distribution throughout the stacks remained the identical, thus leaving us with no extra perception. We turned to JVM-specific profiling, beginning with the essential hotspot stats, after which switching to extra detailed JFR (Java Flight Recorder) captures to match the distribution of the occasions. Once more, we got here away empty-handed as there was no noticeable distinction within the quantity or the distribution of the occasions between the “gradual” and “quick” nodes. Nonetheless suspecting one thing is likely to be off with JIT conduct, we ran some fundamental stats in opposition to image maps obtained by perf-map-agent solely to hit one other lifeless finish.
Satisfied we’re not lacking something on the app-, OS- and JVM- ranges, we felt the reply is likely to be hidden at a decrease degree. Fortunately, the m5.12xl occasion sort exposes a set of core PMCs (Efficiency Monitoring Counters, a.okay.a. PMU counters), so we began by gathering a baseline set of counters utilizing PerfSpect:
Within the desk above, the nodes exhibiting low CPU and low latency signify a “quick node”, whereas the nodes with larger CPU/latency signify a “gradual node”. Apart from apparent CPU variations, we will see that the gradual node has virtually 3x CPI (Cycles Per Instruction) of the quick node. We additionally see a lot larger L1 cache exercise mixed with 4x larger depend of MACHINE_CLEARS. One frequent trigger of those signs is so-called “false sharing” — a utilization sample occurring when 2 cores studying from / writing to unrelated variables that occur to share the identical L1 cache line. Cache line is an idea just like reminiscence web page — a contiguous chunk of knowledge (usually 64 bytes on x86 methods) transferred to and from the cache. This diagram illustrates it:
Every core on this diagram has its personal non-public cache. Since each cores are accessing the identical reminiscence house, caches should be constant. This consistency is ensured with so-called “cache coherency protocol.” As Thread 0 writes to the “crimson” variable, coherency protocol marks the entire cache line as “modified” in Thread 0’s cache and as “invalidated” in Thread 1’s cache. Later, when Thread 1 reads the “blue” variable, despite the fact that the “blue” variable shouldn’t be modified, coherency protocol forces your complete cache line to be reloaded from the cache that had the final modification — Thread 0’s cache on this instance. Resolving coherency throughout non-public caches takes time and causes CPU stalls. Moreover, ping-ponging coherency site visitors needs to be monitored by the final degree shared cache’s controller, which results in much more stalls. We take CPU cache consistency as a right, however this “false sharing” sample illustrates there’s an enormous efficiency penalty for merely studying a variable that’s neighboring with another unrelated knowledge.
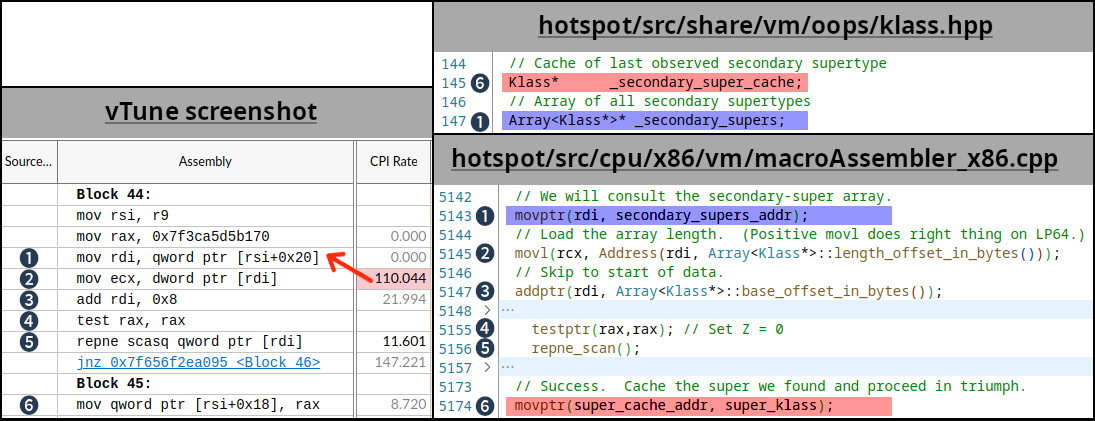
Armed with this data, we used Intel vTune to run microarchitecture profiling. Drilling down into “sizzling” strategies and additional into the meeting code confirmed us blocks of code with some directions exceeding 100 CPI, which is extraordinarily gradual. That is the abstract of our findings:
Numbered markers from 1 to six denote the identical code/variables throughout the sources and vTune meeting view. The crimson arrow signifies that the CPI worth possible belongs to the earlier instruction — that is as a result of profiling skid in absence of PEBS (Processor Occasion-Based mostly Sampling), and often it’s off by a single instruction. Based mostly on the truth that (5) “repne scan” is a reasonably uncommon operation within the JVM codebase, we had been capable of hyperlink this snippet to the routine for subclass checking (the identical code exists in JDK mainline as of the writing of this blogpost). Going into the main points of subtype checking in HotSpot is way past the scope of this blogpost, however curious readers can be taught extra about it from the 2002 publication Quick Subtype Checking within the HotSpot JVM. As a result of nature of the category hierarchy used on this explicit workload, we hold hitting the code path that retains updating (6) the “_secondary_super_cache” subject, which is a single-element cache for the last-found secondary superclass. Be aware how this subject is adjoining to the “_secondary_supers”, which is an inventory of all superclasses and is being learn (1) to start with of the scan. A number of threads do these read-write operations, and if fields (1) and (6) fall into the identical cache line, then we hit a false sharing use case. We highlighted these fields with crimson and blue colours to connect with the false sharing diagram above.
Be aware that for the reason that cache line measurement is 64 bytes and the pointer measurement is 8 bytes, we now have a 1 in 8 probability of those fields falling on separate cache traces, and a 7 in 8 probability of them sharing a cache line. This 1-in-8 probability is 12.5%, matching our earlier commentary on the proportion of the “quick” nodes. Fascinating!
Though the repair concerned patching the JDK, it was a easy change. We inserted padding between “_secondary_super_cache” and “_secondary_supers” fields to make sure they by no means fall into the identical cache line. Be aware that we didn’t change the purposeful side of JDK conduct, however reasonably the information structure:
The outcomes of deploying the patch had been instantly noticeable. The graph under is a breakdown of CPU by node. Right here we will see a red-black deployment occurring at midday, and the brand new ASG with the patched JDK taking up by 12:15:
Each CPU and latency (graph omitted for brevity) confirmed an identical image — the “gradual” band of nodes was gone!
We didn’t have a lot time to marvel at these outcomes, nevertheless. Because the autoscaling reached our CPU goal, we seen that we nonetheless couldn’t push greater than ~150 RPS per node — properly wanting our objective of ~250 RPS. One other spherical of vTune profiling on the patched JDK model confirmed the identical bottleneck round secondary superclass cache lookup. It was puzzling at first to see seemingly the identical downside coming again proper after we put in a repair, however upon nearer inspection we realized we’re coping with “true sharing” now. In contrast to “false sharing,” the place 2 unbiased variables share a cache line, “true sharing” refers back to the similar variable being learn and written by a number of threads/cores. On this case, CPU-enforced reminiscence ordering is the reason for slowdown. We reasoned that eradicating the impediment of false sharing and rising the general throughput resulted in elevated execution of the identical JVM superclass caching code path. Basically, we now have larger execution concurrency, inflicting extreme strain on the superclass cache on account of CPU-enforced reminiscence ordering protocols. The frequent method to resolve that is to keep away from writing to the shared variable altogether, successfully bypassing the JVM’s secondary superclass cache. Since this modification altered the conduct of the JDK, we gated it behind a command line flag. That is the whole lot of our patch:
And listed below are the outcomes of operating with disabled superclass cache writes:
Our repair pushed the throughput to ~350 RPS on the similar CPU autoscaling goal of 55%. To place this in perspective, that’s a 3.5x enchancment over the throughput we initially reached on m5.12xl, together with a discount in each common and tail latency.
Disabling writes to the secondary superclass cache labored properly in our case, and despite the fact that this won’t be a fascinating resolution in all instances, we needed to share our methodology, toolset and the repair within the hope that it might assist others encountering related signs. Whereas working by this downside, we got here throughout JDK-8180450 — a bug that’s been dormant for greater than 5 years that describes precisely the issue we had been going through. It appears ironic that we couldn’t discover this bug till we truly found out the reply. We imagine our findings complement the good work that has been completed in diagnosing and remediating it.
We have a tendency to think about trendy JVMs as extremely optimized runtime environments, in lots of instances rivaling extra “performance-oriented” languages like C++. Whereas it holds true for almost all of workloads, we had been reminded that efficiency of sure workloads operating inside JVMs might be affected not solely by the design and implementation of the appliance code, but in addition by the implementation of the JVM itself. On this blogpost we described how we had been capable of leverage PMCs to be able to discover a bottleneck within the JVM’s native code, patch it, and subsequently notice higher than a threefold improve in throughput for the workload in query. In terms of this class of efficiency points, the power to introspect the execution on the degree of CPU microarchitecture proved to be the one resolution. Intel vTune gives precious perception even with the core set of PMCs, reminiscent of these uncovered by m5.12xl occasion sort. Exposing a extra complete set of PMCs together with PEBS throughout all occasion sorts and sizes within the cloud atmosphere would pave the way in which for deeper efficiency evaluation and doubtlessly even bigger efficiency positive factors.







