













How Netflix’s Container Platform Connects Linux Kernel Panics to Kubernetes Pods
By Kyle Anderson
With a latest effort to scale back buyer (engineers, not finish customers) ache on our container platform Titus, I began investigating “orphaned” pods. There are pods that by no means obtained to complete and needed to be rubbish collected with no actual passable ultimate standing. Our Service job (suppose ReplicatSet) house owners don’t care an excessive amount of, however our Batch customers care lots. And not using a actual return code, how can they know whether it is protected to retry or not?
These orphaned pods signify actual ache for our customers, even when they’re a small proportion of the entire pods within the system. The place are they going, precisely? Why did they go away?
This weblog submit reveals join the dots from the worst case situation (a kernel panic) by way of to Kubernetes (k8s) and ultimately as much as us operators in order that we will monitor how and why our k8s nodes are going away.
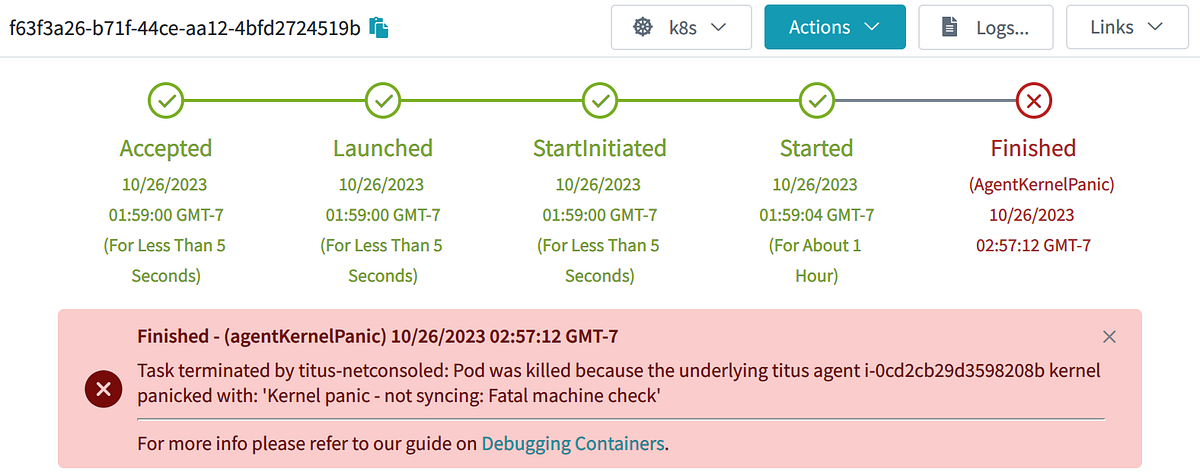
Orphaned pods get misplaced as a result of the underlying k8s node object goes away. As soon as that occurs a GC course of deletes the pod. On Titus we run a customized controller to retailer the historical past of Pod and Node objects, in order that we will avoid wasting clarification and present it to our customers. This failure mode seems to be like this in our UI:
That is an clarification, nevertheless it wasn’t very satisfying to me or to our customers. Why was the agent misplaced?
Nodes can go away for any purpose, particularly in “the cloud”. When this occurs, normally a k8s cloud-controller offered by the cloud vendor will detect that the precise server, in our case an EC2 Occasion, has really gone away, and can in flip delete the k8s node object. That also doesn’t actually reply the query of why.
How can we guarantee that each occasion that goes away has a purpose, account for that purpose, and bubble it up all the best way to the pod? All of it begins with an annotation:
{
"apiVersion": "v1",
"variety": "Pod",
"metadata": {
"annotations": {
"pod.titus.netflix.com/pod-termination-reason": "One thing actually unhealthy occurred!",
...
Simply making a spot to place this knowledge is a good begin. Now all we’ve got to do is make our GC controllers conscious of this annotation, after which sprinkle it into any course of that might probably make a pod or node go away unexpectedly. Including an annotation (versus patching the standing) preserves the remainder of the pod as-is for historic functions. (We additionally add annotations for what did the terminating, and a brief reason-code for tagging)
The pod-termination-reason annotation is helpful to populate human readable messages like:
- “This pod was preempted by the next precedence job ($id)”
- “This pod needed to be terminated as a result of the underlying {hardware} failed ($failuretype)”
- “This pod needed to be terminated as a result of $person ran sudo halt on the node”
- “This pod died unexpectedly as a result of the underlying node kernel panicked!”
However wait, how are we going to annotate a pod for a node that kernel panicked?
When the Linux kernel panics, there may be simply not a lot you are able to do. However what if you happen to may ship out some form of “with my ultimate breath, I curse Kubernetes!” UDP packet?
Impressed by this Google Spanner paper, the place Spanner nodes ship out a “final gasp” UDP packet to launch leases & locks, you can also configure your servers to do the identical upon kernel panic utilizing a inventory Linux module: netconsole.
The truth that the Linux kernel may even ship out UDP packets with the string ‘kernel panic’, whereas it’s panicking, is type of wonderful. This works as a result of netconsole must be configured with virtually your entire IP header crammed out already beforehand. That’s proper, it’s a must to inform Linux precisely what your supply MAC, IP, and UDP Port are, in addition to the vacation spot MAC, IP, and UDP ports. You’re virtually developing the UDP packet for the kernel. However, with that prework, when the time comes, the kernel can simply assemble the packet and get it out the (preconfigured) community interface as issues come crashing down. Fortunately the netconsole-setup command makes the setup fairly simple. All of the configuration choices could be set dynamically as effectively, in order that when the endpoint modifications one can level to the brand new IP.
As soon as that is setup, kernel messages will begin flowing proper after modprobe. Think about the entire thing working like a dmesg | netcat -u $vacation spot 6666, however in kernel area.
With netconsole setup, the final gasp from a crashing kernel seems to be like a set of UDP packets precisely like one may anticipate, the place the info of the UDP packet is solely the textual content of the kernel message. Within the case of a kernel panic, it would look one thing like this (one UDP packet per line):
Kernel panic - not syncing: buffer overrun at 0x4ba4c73e73acce54
[ 8374.456345] CPU: 1 PID: 139616 Comm: insmod Kdump: loaded Tainted: G OE
[ 8374.458506] {Hardware} identify: Amazon EC2 r5.2xlarge/, BIOS 1.0 10/16/2017
[ 8374.555629] Name Hint:
[ 8374.556147] <TASK>
[ 8374.556601] dump_stack_lvl+0x45/0x5b
[ 8374.557361] panic+0x103/0x2db
[ 8374.558166] ? __cond_resched+0x15/0x20
[ 8374.559019] ? do_init_module+0x22/0x20a
[ 8374.655123] ? 0xffffffffc0f56000
[ 8374.655810] init_module+0x11/0x1000 [kpanic]
[ 8374.656939] do_one_initcall+0x41/0x1e0
[ 8374.657724] ? __cond_resched+0x15/0x20
[ 8374.658505] ? kmem_cache_alloc_trace+0x3d/0x3c0
[ 8374.754906] do_init_module+0x4b/0x20a
[ 8374.755703] load_module+0x2a7a/0x3030
[ 8374.756557] ? __do_sys_finit_module+0xaa/0x110
[ 8374.757480] __do_sys_finit_module+0xaa/0x110
[ 8374.758537] do_syscall_64+0x3a/0xc0
[ 8374.759331] entry_SYSCALL_64_after_hwframe+0x62/0xcc
[ 8374.855671] RIP: 0033:0x7f2869e8ee69
...
The final piece is to attach is Kubernetes (k8s). We want a k8s controller to do the next:
- Pay attention for netconsole UDP packets on port 6666, awaiting issues that appear like kernel panics from nodes.
- Upon kernel panic, lookup the k8s node object related to the IP deal with of the incoming netconsole packet.
- For that k8s node, discover all of the pods sure to it, annotate, then delete these pods (they’re toast!).
- For that k8s node, annotate the node after which delete it too (it’s also toast!).
Elements 1&2 may appear like this:
for {
n, addr, err := serverConn.ReadFromUDP(buf)
if err != nil {
klog.Errorf("Error ReadFromUDP: %s", err)
} else {
line := santizeNetConsoleBuffer(buf[0:n])
if isKernelPanic(line) {
panicCounter = 20
go handleKernelPanicOnNode(ctx, addr, nodeInformer, podInformer, kubeClient, line)
}
}
if panicCounter > 0 {
klog.Infof("KernelPanic context from %s: %s", addr.IP, line)
panicCounter++
}
}
After which elements 3&4 may appear like this:
func handleKernelPanicOnNode(ctx context.Context, addr *internet.UDPAddr, nodeInformer cache.SharedIndexInformer, podInformer cache.SharedIndexInformer, kubeClient kubernetes.Interface, line string) {
node := getNodeFromAddr(addr.IP.String(), nodeInformer)
if node == nil {
klog.Errorf("Received a kernel panic from %s, however could not discover a k8s node object for it?", addr.IP.String())
} else {
pods := getPodsFromNode(node, podInformer)
klog.Infof("Received a kernel panic from node %s, annotating and deleting all %d pods and that node.", node.Title, len(pods))
annotateAndDeletePodsWithReason(ctx, kubeClient, pods, line)
err := deleteNode(ctx, kubeClient, node.Title)
if err != nil {
klog.Errorf("Error deleting node %s: %s", node.Title, err)
} else {
klog.Infof("Deleted panicked node %s", node.Title)
}
}
}
With that code in place, as quickly as a kernel panic is detected, the pods and nodes instantly go away. No want to attend for any GC course of. The annotations assist doc what occurred to the node & pod:
Marking {that a} job failed due to a kernel panic might not be that passable to our prospects. However they will take satisfaction in understanding that we now have the required observability instruments to start out fixing these kernel panics!
Do you additionally get pleasure from actually attending to the underside of why issues fail in your programs or suppose kernel panics are cool? Be part of us on the Compute Crew the place we’re constructing a world-class container platform for our engineers.






