










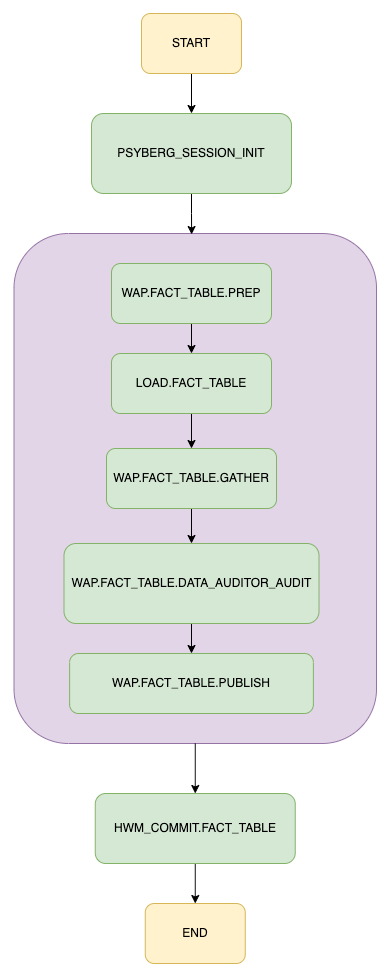
Let’s use the signup reality desk for example right here. This desk’s workflow runs hourly, with the primary enter supply being an Iceberg desk storing all uncooked signup occasions partitioned by touchdown date, hour, and batch id.
Right here’s a YAML snippet outlining the configuration for this throughout the Psyberg initialization step:
- job:
id: psyberg_session_init
kind: Spark
spark:
app_args:
- --process_name=signup_fact_load
- --src_tables=raw_signups
- --psyberg_session_id=20230914061001
- --psyberg_hwm_table=high_water_mark_table
- --psyberg_session_table=psyberg_session_metadata
- --etl_pattern_id=1
Behind the scenes, Psyberg identifies that this pipeline is configured for a stateless sample since etl_pattern_id=1.
Psyberg additionally makes use of the offered inputs to detect the Iceberg snapshots that continued after the most recent excessive watermark out there within the watermark desk. Utilizing the abstract column in snapshot metadata [see the Iceberg Metadata section in post 1 for more details], we parse out the partition info for every Iceberg snapshot of the supply desk.
Psyberg then retains these processing URIs (an array of JSON strings containing mixtures of touchdown date, hour, and batch IDs) as decided by the snapshot modifications. This info and different calculated metadata are saved within the psyberg_session_f desk. This saved knowledge is then out there for the following LOAD.FACT_TABLE job within the workflow to make the most of and for evaluation and debugging functions.
Stateful Information Processing is used when the output is dependent upon a sequence of occasions throughout a number of enter streams.
Let’s think about the instance of making a cancel reality desk, which takes the next as enter:
- Uncooked cancellation occasions indicating when the shopper account was canceled
- A reality desk that shops incoming buyer requests to cancel their subscription on the finish of the billing interval
These inputs assist derive extra stateful analytical attributes like the kind of churn i.e. voluntary or involuntary, and so on.
The initialization step for Stateful Information Processing differs barely from Stateless. Psyberg affords extra configurations in accordance with the pipeline wants. Right here’s a YAML snippet outlining the configuration for the cancel reality desk throughout the Psyberg initialization step:
- job:
id: psyberg_session_init
kind: Spark
spark:
app_args:
- --process_name=cancel_fact_load
- --src_tables=raw_cancels|processing_ts,cancel_request_fact
- --psyberg_session_id=20230914061501
- --psyberg_hwm_table=high_water_mark_table
- --psyberg_session_table=psyberg_session_metadata
- --etl_pattern_id=2
Behind the scenes, Psyberg identifies that this pipeline is configured for a stateful sample since etl_pattern_id is 2.
Discover the extra element within the src_tables checklist akin to raw_cancels above. The processing_ts right here represents the occasion processing timestamp which is completely different from the common Iceberg snapshot commit timestamp i.e. event_landing_ts as described partly 1 of this sequence.
It is very important seize the vary of a consolidated batch of occasions from all of the sources i.e. each raw_cancels and cancel_request_fact, whereas factoring in late-arriving occasions. Adjustments to the supply desk snapshots may be tracked utilizing completely different timestamp fields. Realizing which timestamp subject to make use of i.e. event_landing_ts or one thing like processing_ts helps keep away from lacking occasions.
Much like the method in stateless knowledge processing, Psyberg makes use of the offered inputs to parse out the partition info for every Iceberg snapshot of the supply desk.






