












13 hours in the past
by Jun He, Yingyi Zhang, and Pawan Dixit
Incremental processing is an strategy to course of new or modified knowledge in workflows. The important thing benefit is that it solely incrementally processes knowledge which can be newly added or up to date to a dataset, as a substitute of re-processing the entire dataset. This not solely reduces the price of compute sources but in addition reduces the execution time in a major method. When workflow execution has a shorter period, possibilities of failure and handbook intervention scale back. It additionally improves the engineering productiveness by simplifying the present pipelines and unlocking the brand new patterns.
On this weblog put up, we discuss in regards to the panorama and the challenges in workflows at Netflix. We’ll present how we’re constructing a clear and environment friendly incremental processing answer (IPS) through the use of Netflix Maestro and Apache Iceberg. IPS supplies the incremental processing assist with knowledge accuracy, knowledge freshness, and backfill for customers and addresses lots of the challenges in workflows. IPS allows customers to proceed to make use of the information processing patterns with minimal modifications.
Netflix depends on knowledge to energy its enterprise in all phases. Whether or not in analyzing A/B exams, optimizing studio manufacturing, coaching algorithms, investing in content material acquisition, detecting safety breaches, or optimizing funds, nicely structured and correct knowledge is foundational. As our enterprise scales globally, the demand for knowledge is rising and the wants for scalable low latency incremental processing start to emerge. There are three frequent points that the dataset house owners normally face.
- Knowledge Freshness: Giant datasets from Iceberg tables wanted to be processed rapidly and precisely to generate insights to allow quicker product selections. The hourly processing semantics together with legitimate–through-timestamp watermark or knowledge indicators supplied by the Knowledge Platform toolset right now satisfies many use circumstances, however will not be the most effective for low-latency batch processing. Earlier than IPS, the Knowledge Platform didn’t have an answer for monitoring the state and development of knowledge units as a single simple to make use of providing. This has led to a couple inside options comparable to Psyberg. These inside libraries course of knowledge by capturing the modified partitions, which works solely on particular use circumstances. Moreover, the libraries have tight coupling to the consumer enterprise logic, which frequently incurs greater migration prices, upkeep prices, and requires heavy coordination with the Knowledge Platform group.
- Knowledge Accuracy: Late arriving knowledge causes datasets processed previously to turn into incomplete and in consequence inaccurate. To compensate for that, ETL workflows usually use a lookback window, based mostly on which they reprocess the information in that sure time window. For instance, a job would reprocess aggregates for the previous 3 days as a result of it assumes that there can be late arriving knowledge, however knowledge prior to three days isn’t value the price of reprocessing.
- Backfill: Backfilling datasets is a standard operation in large knowledge processing. This requires repopulating knowledge for a historic time interval which is earlier than the scheduled processing. The necessity for backfilling could possibly be on account of a wide range of components, e.g. (1) upstream knowledge units bought repopulated on account of modifications in enterprise logic of its knowledge pipeline, (2) enterprise logic was modified in an information pipeline, (3) anew metric was created that must be populated for historic time ranges, (4) historic knowledge was discovered lacking, and so forth.
These challenges are presently addressed in suboptimal and fewer value environment friendly methods by particular person native groups to satisfy the wants, comparable to
- Lookback: This can be a generic and easy strategy that knowledge engineers use to unravel the information accuracy drawback. Customers configure the workflow to learn the information in a window (e.g. previous 3 hours or 10 days). The window is about based mostly on customers’ area information in order that customers have a excessive confidence that the late arriving knowledge will probably be included or is not going to matter (i.e. knowledge arrives too late to be helpful). It ensures the correctness with a excessive value when it comes to time and compute sources.
- Foreach sample: Customers construct backfill workflows utilizing Maestro foreach assist. It really works nicely to backfill knowledge produced by a single workflow. If the pipeline has a number of phases or many downstream workflows, customers should manually create backfill workflows for every of them and that requires important handbook work.
The incremental processing answer (IPS) described right here has been designed to deal with the above issues. The design objective is to offer a clear and simple to undertake answer for the Incremental processing to make sure knowledge freshness, knowledge accuracy, and to offer simple backfill assist.
- Knowledge Freshness: present the assist for scheduling workflows in a micro batch trend (e.g. 15 min interval) with state monitoring performance
- Knowledge Accuracy: present the assist to course of all late arriving knowledge to realize knowledge accuracy wanted by the enterprise with considerably improved efficiency when it comes to multifold time and price effectivity
- Backfill: present managed backfill assist to construct, monitor, and validate the backfill, together with routinely propagating modifications from upstream to downstream workflows, to vastly enhance engineering productiveness (i.e. a number of days or even weeks of engineering work to construct backfill workflows vs one click on for managed backfill)
Normal Idea
Incremental processing is an strategy to course of knowledge in batch — however solely on new or modified knowledge. To assist incremental processing, we want an strategy for not solely capturing incremental knowledge modifications but in addition monitoring their states (i.e. whether or not a change is processed by a workflow or not). It should pay attention to the change and may seize the modifications from the supply desk(s) after which preserve monitoring these modifications. Right here, modifications imply extra than simply new knowledge itself. For instance, a row in an aggregation goal desk wants all of the rows from the supply desk related to the aggregation row. Additionally, if there are a number of supply tables, normally the union of the modified knowledge ranges from all enter tables offers the complete change knowledge set. Thus, change data captured should embody all associated knowledge together with these unchanged rows within the supply desk as nicely. Resulting from beforehand talked about complexities, change monitoring can’t be merely achieved through the use of a single watermark. IPS has to trace these captured modifications in finer granularity.
The modifications from the supply tables would possibly have an effect on the reworked outcome within the goal desk in varied methods.
- If one row within the goal desk is derived from one row within the supply desk, newly captured knowledge change would be the full enter dataset for the workflow pipeline.
- If one row within the goal desk is derived from a number of rows within the supply desk, capturing new knowledge will solely inform us the rows should be re-processed. However the dataset wanted for ETL is past the change knowledge itself. For instance, an aggregation based mostly on account id requires all rows from the supply desk about an account id. The change dataset will inform us which account ids are modified after which the consumer enterprise logic must load all knowledge related to these account ids discovered within the change knowledge.
- If one row within the goal desk is derived based mostly on the information past the modified knowledge set, e.g. becoming a member of supply desk with different tables, newly captured knowledge remains to be helpful and may point out a spread of knowledge to be affected. Then the workflow will re-process the information based mostly on the vary. For instance, assuming we have now a desk that retains the amassed view time for a given account partitioned by the day. If the view time 3-days in the past is up to date proper now on account of late arriving knowledge, then the view time for the next two days must be re-calculated for this account. On this case, the captured late arriving knowledge will inform us the beginning of the re-calculation, which is far more correct than recomputing all the things for the previous X days by guesstimate, the place X is a cutoff lookback window determined by enterprise area information.
As soon as the change data (knowledge or vary) is captured, a workflow has to jot down the information to the goal desk in a barely extra difficult manner as a result of the straightforward INSERT OVERWRITE mechanism received’t work nicely. There are two alternate options:
- Merge sample: In some compute frameworks, e.g. Spark 3, it helps MERGE INTO to permit new knowledge to be merged into the present knowledge set. That solves the write drawback for incremental processing. Notice that the workflow/step may be safely restarted with out worrying about duplicate knowledge being inserted when utilizing MERGE INTO.
- Append sample: Customers may use append solely write (e.g. INSERT INTO) so as to add the brand new knowledge to the present knowledge set. As soon as the processing is accomplished, the append knowledge is dedicated to the desk. If customers need to re-run or re-build the information set, they may run a backfill workflow to fully overwrite the goal knowledge set (e.g. INSERT OVERWRITE).
Moreover, the IPS will naturally assist the backfill in lots of circumstances. Downstream workflows (if there isn’t a enterprise logic change) will probably be triggered by the information change on account of backfill. This permits auto propagation of backfill knowledge in multi-stage pipelines. Notice that the backfill assist is skipped on this weblog. We’ll discuss IPS backfill assist in one other following weblog put up.
Netflix Maestro
Maestro is the Netflix knowledge workflow orchestration platform constructed to fulfill the present and future wants of Netflix. It’s a general-purpose workflow orchestrator that gives a totally managed workflow-as-a-service (WAAS) to the information platform customers at Netflix. It serves 1000’s of customers, together with knowledge scientists, knowledge engineers, machine studying engineers, software program engineers, content material producers, and enterprise analysts, in varied use circumstances. Maestro is very scalable and extensible to assist present and new use circumstances and presents enhanced usability to finish customers.
Because the final weblog on Maestro, we have now migrated all of the workflows to it on behalf of customers with minimal interruption. Maestro has been absolutely deployed in manufacturing with 100% workload working on it.
IPS is constructed upon Maestro as an extension by including two constructing blocks, i.e. a brand new set off mechanism and step job sort, to allow incremental processing for all workflows. It’s seamlessly built-in into the entire Maestro ecosystem with minimal onboarding value.
Apache Iceberg
Iceberg is a high-performance format for large analytic tables. Iceberg brings the reliability and ease of SQL tables to large knowledge, whereas making it potential for engines like Spark, Trino, Flink, Presto, Hive and Impala to soundly work with the identical tables, on the similar time. It helps expressive SQL, full schema evolution, hidden partitioning, knowledge compaction, and time journey & rollback. Within the IPS, we leverage the wealthy options supplied by Apache Iceberg to develop a light-weight strategy to seize the desk modifications.
Incremental Change Seize Design
Utilizing Netflix Maestro and Apache Iceberg, we created a novel answer for incremental processing, which supplies the incremental change (knowledge and vary) seize in an excellent light-weight manner with out copying any knowledge. Throughout our exploration, we see an enormous alternative to enhance value effectivity and engineering productiveness utilizing incremental processing.
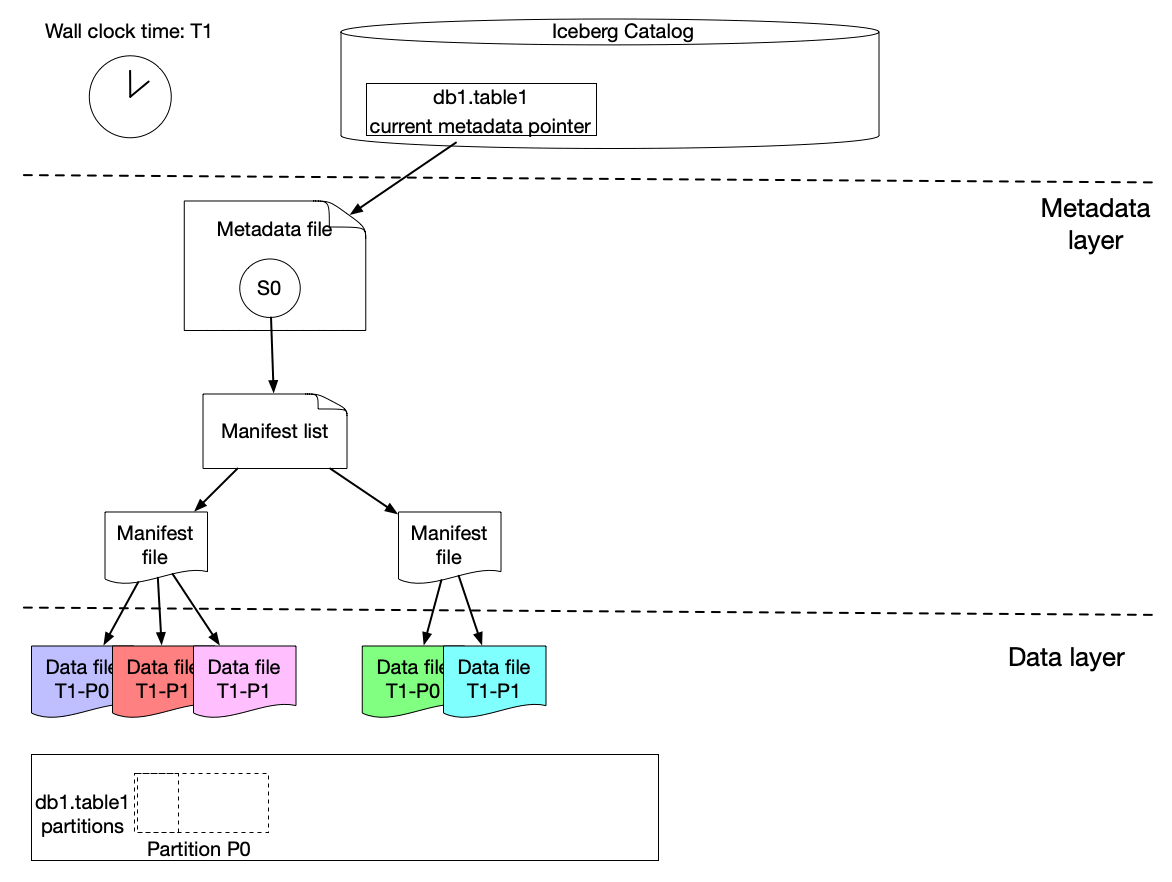
Right here is our answer to realize incremental change seize constructed upon Apache Iceberg options. As we all know, an iceberg desk accommodates a listing of snapshots with a set of metadata knowledge. Snapshots embody references to the precise immutable knowledge recordsdata. A snapshot can comprise knowledge recordsdata from completely different partitions.
The graph above exhibits that s0 accommodates knowledge for Partition P0 and P1 at T1. Then at T2, a brand new snapshot s1 is dedicated to the desk with a listing of latest knowledge recordsdata, which incorporates late arriving knowledge for partition P0 and P1 and knowledge for P2.
We carried out a light-weight strategy to create an iceberg desk (referred to as ICDC desk), which has its personal snapshot however solely contains the brand new knowledge file references from the unique desk with out copying the information recordsdata. It’s extremely environment friendly with a low value. Then workflow pipelines can simply load the ICDC desk to course of solely the change knowledge from partition P0, P1, P2 with out reprocessing the unchanged knowledge in P0 and P1. In the meantime, the change vary can also be captured for the desired knowledge area because the Iceberg desk metadata accommodates the higher and decrease certain data of every knowledge area for every knowledge file. Furthermore, IPS will monitor the modifications in knowledge file granularity for every workflow.
This light-weight strategy is seamlessly built-in with Maestro to permit all (1000’s) scheduler customers to make use of this new constructing block (i.e. incremental processing) of their tens of 1000’s of workflows. Every workflow utilizing IPS will probably be injected with a desk parameter, which is the desk title of the light-weight ICDC desk. The ICDC desk accommodates solely the change knowledge. Moreover, if the workflow wants the change vary, a listing of parameters will probably be injected to the consumer workflow to incorporate the change vary data. The incremental processing may be enabled by a brand new step job sort (ICDC) and/or a brand new incremental set off mechanism. Customers can use them along with all present Maestro options, e.g. foreach patterns, step dependencies based mostly on legitimate–through-timestamp watermark, write-audit-publish templatized sample, and so forth.
Most important Benefits
With this design, consumer workflows can undertake incremental processing with very low efforts. The consumer enterprise logic can also be decoupled from the IPS implementation. Multi-stage pipelines may combine the incremental processing workflows with present regular workflows. We additionally discovered that consumer workflows may be simplified after utilizing IPS by eradicating further steps to deal with the complexity of the lookback window or calling some inside libraries.
Including incremental processing options into Netflix Maestro as new options/constructing blocks for customers will allow customers to construct their workflows in a way more environment friendly manner and bridge the gaps to unravel many difficult issues (e.g. coping with late arriving knowledge) in a a lot less complicated manner.
Whereas onboarding consumer pipelines to IPS, we have now found a number of incremental processing patterns:
Incrementally course of the captured incremental change knowledge and instantly append them to the goal desk
That is the easy incremental processing use case, the place the change knowledge carries all the data wanted for the information processing. Upstream modifications (normally from a single supply desk) are propagated to the downstream (normally one other goal desk) and the workflow pipeline solely must course of the change knowledge (would possibly be a part of with different dimension tables) after which merge into (normally append) to the goal desk. This sample will substitute lookback window patterns to care for late arriving knowledge. As an alternative of overwriting previous X days of knowledge fully through the use of a lookback window sample, consumer workflows simply have to MERGE the change knowledge (together with late arriving knowledge) into the goal desk by processing the ICDC desk.
Use captured incremental change knowledge because the row degree filter listing to take away pointless transformation
ETL jobs normally have to combination knowledge based mostly on sure group-by keys. Change knowledge will disclose all of the group-by keys that require a re-aggregation as a result of new touchdown knowledge from the supply desk(s). Then ETL jobs can be a part of the unique supply desk with the ICDC desk on these group-by keys through the use of ICDC as a filter to hurry up the processing to allow calculations of a a lot smaller set of knowledge. There isn’t a change to enterprise rework logic and no re-design of ETL workflow. ETL pipelines preserve all the advantages of batch workflows.
Use the captured vary parameters within the enterprise logic
This sample is normally utilized in difficult use circumstances, comparable to becoming a member of a number of tables and doing complicated processings. On this case, the change knowledge don’t give the complete image of the enter wanted by the ETL workflow. As an alternative, the change knowledge signifies a spread of modified knowledge units for a selected set of fields (could be partition keys) in a given enter desk or normally a number of enter tables. Then, the union of the change ranges from all enter tables offers the complete change knowledge set wanted by the workflow. Moreover, the entire vary of knowledge normally must be overwritten as a result of the transformation will not be stateless and will depend on the result outcome from the earlier ranges. One other instance is that the aggregated document within the goal desk or window perform within the question must be up to date based mostly on the entire knowledge set within the partition (e.g. calculating a medium throughout the entire partition). Mainly, the vary derived from the change knowledge signifies the dataset to be re-processed.
Knowledge workflows at Netflix normally should cope with late arriving knowledge which is often solved through the use of lookback window sample on account of its simplicity and ease of implementation. Within the lookback sample, the ETL pipeline will all the time eat the previous X variety of partition knowledge from the supply desk after which overwrite the goal desk in each run. Right here, X is a quantity determined by the pipeline house owners based mostly on their area experience. The disadvantage is the price of computation and execution time. It normally prices virtually X instances greater than the pipeline with out contemplating late arriving knowledge. Given the truth that the late arriving knowledge is sparse, the vast majority of the processing is finished on the information which were already processed, which is pointless. Additionally, observe that this strategy is predicated on area information and typically is topic to modifications of the enterprise setting or the area experience of knowledge engineers. In sure circumstances, it’s difficult to provide you with an excellent fixed quantity.
Beneath, we are going to use a two-stage knowledge pipeline for example the way to rebuild it utilizing IPS to enhance the fee effectivity. We’ll observe a major value discount (> 80%) with little modifications within the enterprise logic. On this use case, we are going to set the lookback window measurement X to be 14 days, which varies in numerous actual pipelines.
Authentic Knowledge Pipeline with Lookback Window
- playback_table: an iceberg desk holding playback occasions from consumer gadgets ingested by streaming pipelines with late arriving knowledge, which is sparse, solely about few percents of the information is late arriving.
- playback_daily_workflow: a every day scheduled workflow to course of the previous X days playback_table knowledge and write the reworked knowledge to the goal desk for the previous X days
- playback_daily_table: the goal desk of the playback_daily_workflow and get overwritten every single day for the previous X days
- playback_daily_agg_workflow: a every day scheduled workflow to course of the previous X days’ playback_daily_table knowledge and write the aggregated knowledge to the goal desk for the previous X days
- playback_daily_agg_table: the goal desk of the playback_daily_agg_workflow and get overwritten every single day for the previous 14 days.
We ran this pipeline in a pattern dataset utilizing the true enterprise logic and right here is the typical execution results of pattern runs
- The primary stage workflow takes about 7 hours to course of playback_table knowledge
- The second stage workflow takes about 3.5 hours to course of playback_daily_table knowledge
New Knowledge Pipeline with Incremental Processing
Utilizing IPS, we rewrite the pipeline to keep away from re-processing knowledge as a lot as potential. The brand new pipeline is proven under.
Stage 1:
- ips_playback_daily_workflow: it’s the up to date model of playback_daily_workflow.
- The workflow spark sql job then reads an incremental change knowledge seize (ICDC) iceberg desk (i.e. playback_icdc_table), which solely contains the brand new knowledge added into the playback_table. It contains the late arriving knowledge however doesn’t embody any unchanged knowledge from playback_table.
- The enterprise logic will substitute INSERT OVERWRITE by MERGE INTO SQL question after which the brand new knowledge will probably be merged into the playback_daily_table.
Stage 2:
- IPS captures the modified knowledge of playback_daily_table and likewise retains the change knowledge in an ICDC supply desk (playback_daily_icdc_table). So we don’t have to onerous code the lookback window within the enterprise logic. If there are solely Y days having modified knowledge in playback_daily_table, then it solely must load knowledge for Y days.
- In ips_playback_daily_agg_workflow, the enterprise logic would be the similar for the present day’s partition. We then have to replace enterprise logic to care for late arriving knowledge by
- JOIN the playback_daily desk with playback_daily_icdc_table on the aggregation group-by keys for the previous 2 to X days, excluding the present day (i.e. day 1)
- As a result of late arriving knowledge is sparse, JOIN will slender down the playback_daily_table knowledge set in order to solely course of a really small portion of it.
- The enterprise logic will use MERGE INTO SQL question then the change will probably be propagated to the downstream goal desk
- For the present day, the enterprise logic would be the similar and eat the information from playback_daily_table after which write the result to the goal desk playback_daily_agg_table utilizing INSERT OVERWRITE as a result of there isn’t a want to hitch with the ICDC desk.
With these small modifications, the information pipeline effectivity is vastly improved. In our pattern run,
- The primary stage workflow takes nearly half-hour to course of X day change knowledge from playback_table.
- The second stage workflow takes about quarter-hour to course of change knowledge between day 2 to day X from playback_daily_table by becoming a member of with playback_daily_cdc_table knowledge and takes one other quarter-hour to course of the present day (i.e. day 1) playback_daily_table change knowledge.
Right here the spark job settings are the identical in authentic and new pipelines. So in complete, the brand new IPS based mostly pipeline total wants round 10% of sources (measured by the execution time) to complete.
We’ll enhance IPS to assist extra difficult circumstances past append-only circumstances. IPS will have the ability to preserve monitor of the progress of the desk modifications and assist a number of Iceberg desk change varieties (e.g. append, overwrite, and so forth.). We may also add managed backfill assist into IPS to assist customers to construct, monitor, and validate the backfill.
We’re taking Huge Knowledge Orchestration to the following degree and continually fixing new issues and challenges, please keep tuned. If you’re motivated to unravel massive scale orchestration issues, please be a part of us.
Due to our Product Supervisor Ashim Pokharel for driving the technique and necessities. We’d additionally prefer to thank Andy Chu, Kyoko Shimada, Abhinaya Shetty, Bharath Mummadisetty, John Zhuge, Rakesh Veeramacheneni, and different beautiful colleagues at Netflix for his or her ideas and suggestions whereas growing IPS. We’d additionally prefer to thank Prashanth Ramdas, Eva Tse, Charles Smith, and different leaders of Netflix engineering organizations for his or her constructive suggestions and ideas on the IPS structure and design.






