













David J. Berg, Romain Cledat, Kayla Seeley, Shashank Srikanth, Chaoying Wang, Darin Yu
Netflix makes use of information science and machine studying throughout all sides of the corporate, powering a variety of enterprise functions from our inner infrastructure and content material demand modeling to media understanding. The Machine Studying Platform (MLP) staff at Netflix offers a whole ecosystem of instruments round Metaflow, an open supply machine studying infrastructure framework we began, to empower information scientists and machine studying practitioners to construct and handle quite a lot of ML techniques.
Since its inception, Metaflow has been designed to offer a human-friendly API for constructing information and ML (and at this time AI) functions and deploying them in our manufacturing infrastructure frictionlessly. Whereas human-friendly APIs are pleasant, it’s actually the integrations to our manufacturing techniques that give Metaflow its superpowers. With out these integrations, initiatives could be caught on the prototyping stage, or they must be maintained as outliers exterior the techniques maintained by our engineering groups, incurring unsustainable operational overhead.
Given the very various set of ML and AI use instances we help — at this time we’ve got a whole lot of Metaflow initiatives deployed internally — we don’t anticipate all initiatives to observe the identical path from prototype to manufacturing. As an alternative, we offer a sturdy foundational layer with integrations to our company-wide information, compute, and orchestration platform, in addition to numerous paths to deploy functions to manufacturing easily. On prime of this, groups have constructed their very own domain-specific libraries to help their particular use instances and wishes.
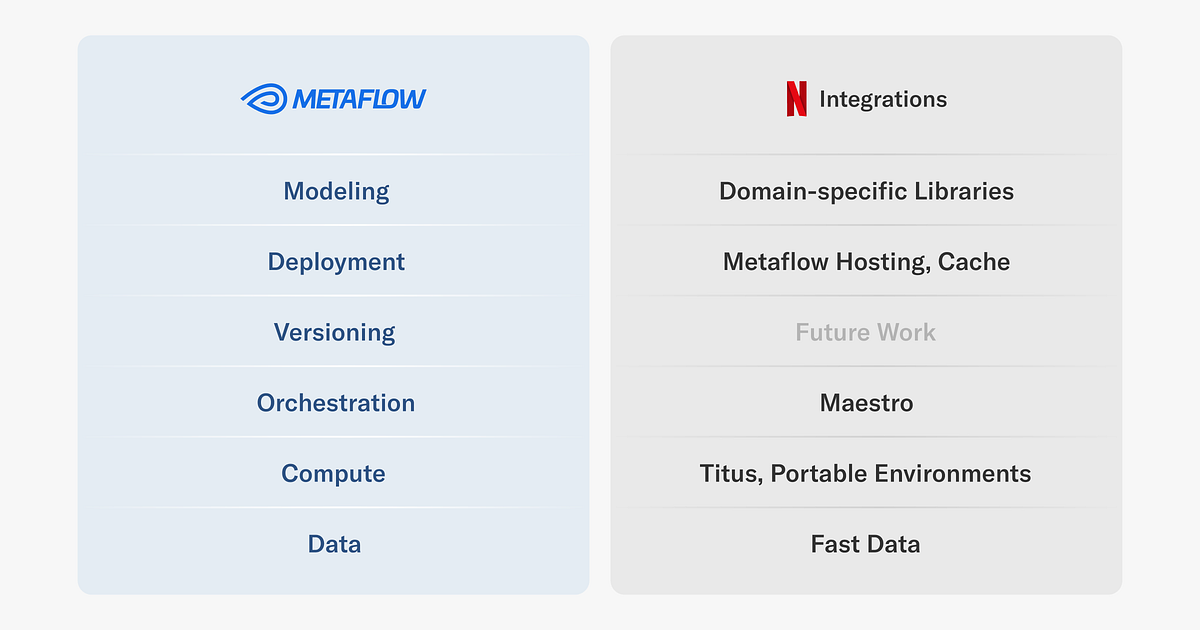
On this article, we cowl just a few key integrations that we offer for numerous layers of the Metaflow stack at Netflix, as illustrated above. We may also showcase real-life ML initiatives that depend on them, to offer an thought of the breadth of initiatives we help. Word that each one initiatives leverage a number of integrations, however we spotlight them within the context of the combination that they use most prominently. Importantly, all of the use instances have been engineered by practitioners themselves.
These integrations are applied via Metaflow’s extension mechanism which is publicly obtainable however topic to vary, and therefore not part of Metaflow’s secure API but. If you’re inquisitive about implementing your individual extensions, get in contact with us on the Metaflow neighborhood Slack.
Let’s go over the stack layer by layer, beginning with probably the most foundational integrations.
Our principal information lake is hosted on S3, organized as Apache Iceberg tables. For ETL and different heavy lifting of knowledge, we primarily depend on Apache Spark. Along with Spark, we wish to help last-mile information processing in Python, addressing use instances corresponding to function transformations, batch inference, and coaching. Often, these use instances contain terabytes of knowledge, so we’ve got to concentrate to efficiency.
To allow quick, scalable, and strong entry to the Netflix information warehouse, we’ve got developed a Quick Knowledge library for Metaflow, which leverages high-performance parts from the Python information ecosystem:
As depicted within the diagram, the Quick Knowledge library consists of two principal interfaces:
- The
Deskobject is chargeable for interacting with the Netflix information warehouse which incorporates parsing Iceberg (or legacy Hive) desk metadata, resolving partitions and Parquet information for studying. Not too long ago, we added help for the write path, so tables will be up to date as nicely utilizing the library. - As soon as we’ve got found the Parquet information to be processed,
MetaflowDataFrametakes over: it downloads information utilizing Metaflow’s high-throughput S3 consumer on to the method’ reminiscence, which frequently outperforms studying of native information.
We use Apache Arrow to decode Parquet and to host an in-memory illustration of knowledge. The consumer can select probably the most appropriate software for manipulating information, corresponding to Pandas or Polars to make use of a dataframe API, or one among our inner C++ libraries for numerous high-performance operations. Due to Arrow, information will be accessed via these libraries in a zero-copy trend.
We additionally take note of dependency points: (Py)Arrow is a dependency of many ML and information libraries, so we don’t need our customized C++ extensions to rely upon a selected model of Arrow, which may simply result in unresolvable dependency graphs. As an alternative, within the fashion of nanoarrow, our Quick Knowledge library solely depends on the secure Arrow C information interface, producing a hermetically sealed library with no exterior dependencies.
Instance use case: Content material Information Graph
Our data graph of the leisure world encodes relationships between titles, actors and different attributes of a movie or sequence, supporting all points of enterprise at Netflix.
A key problem in making a data graph is entity decision. There could also be many alternative representations of barely completely different or conflicting details about a title which have to be resolved. That is sometimes achieved via a pairwise matching process for every entity which turns into non-trivial to do at scale.
This challenge leverages Quick Knowledge and horizontal scaling with Metaflow’s foreach assemble to load giant quantities of title data — roughly a billion pairs — saved within the Netflix Knowledge Warehouse, so the pairs will be matched in parallel throughout many Metaflow duties.
We use metaflow.Desk to resolve all enter shards that are distributed to Metaflow duties that are chargeable for processing terabytes of knowledge collectively. Every job hundreds the information utilizing metaflow.MetaflowDataFrame, performs matching utilizing Pandas, and populates a corresponding shard in an output Desk. Lastly, when all matching is completed and information is written the brand new desk is dedicated so it may be learn by different jobs.
Whereas open-source customers of Metaflow depend on AWS Batch or Kubernetes because the compute backend, we depend on our centralized compute-platform, Titus. Beneath the hood, Titus is powered by Kubernetes, nevertheless it offers a thick layer of enhancements over off-the-shelf Kubernetes, to make it extra observable, safe, scalable, and cost-efficient.
By concentrating on @titus, Metaflow duties profit from these battle-hardened options out of the field, with no in-depth technical data or engineering required from the ML engineers or information scientist finish. Nevertheless, so as to profit from scalable compute, we have to assist the developer to package deal and rehydrate the entire execution surroundings of a challenge in a distant pod in a reproducible method (ideally rapidly). Particularly, we don’t wish to ask builders to handle Docker photos of their very own manually, which rapidly ends in extra issues than it solves.
That is why Metaflow offers help for dependency administration out of the field. Initially, we supported solely @conda, however primarily based on our work on Moveable Execution Environments, open-source Metaflow gained help for @pypi just a few months in the past as nicely.
Instance use case: Constructing mannequin explainers
Right here’s an interesting instance of the usefulness of moveable execution environments. For a lot of of our functions, mannequin explainability issues. Stakeholders like to grasp why fashions produce a sure output and why their habits modifications over time.
There are a number of methods to offer explainability to fashions however a method is to coach an explainer mannequin primarily based on every skilled mannequin. With out going into the small print of how that is achieved precisely, suffice to say that Netflix trains lots of fashions, so we have to prepare lots of explainers too.
Due to Metaflow, we will enable every utility to decide on the most effective modeling strategy for his or her use instances. Correspondingly, every utility brings its personal bespoke set of dependencies. Coaching an explainer mannequin subsequently requires:
- Entry to the unique mannequin and its coaching surroundings, and
- Dependencies particular to constructing the explainer mannequin.
This poses an fascinating problem in dependency administration: we want a higher-order coaching system, “Explainer move” within the determine beneath, which is ready to take a full execution surroundings of one other coaching system as an enter and produce a mannequin primarily based on it.
Explainer move is event-triggered by an upstream move, such Mannequin A, B, C flows within the illustration. The build_environment step makes use of the metaflow surroundings command supplied by our moveable environments, to construct an surroundings that features each the necessities of the enter mannequin in addition to these wanted to construct the explainer mannequin itself.
The constructed surroundings is given a singular title that is determined by the run identifier (to offer uniqueness) in addition to the mannequin kind. Given this surroundings, the train_explainer step is then in a position to consult with this uniquely named surroundings and function in an surroundings that may each entry the enter mannequin in addition to prepare the explainer mannequin. Word that, in contrast to in typical flows utilizing vanilla @conda or @pypi, the moveable environments extension permits customers to additionally fetch these environments immediately at execution time versus at deploy time which subsequently permits customers to, as on this case, resolve the surroundings proper earlier than utilizing it within the subsequent step.
If information is the gas of ML and the compute layer is the muscle, then the nerves have to be the orchestration layer. We have now talked in regards to the significance of a production-grade workflow orchestrator within the context of Metaflow after we launched help for AWS Step Capabilities years in the past. Since then, open-source Metaflow has gained help for Argo Workflows, a Kubernetes-native orchestrator, in addition to help for Airflow which continues to be extensively utilized by information engineering groups.
Internally, we use a manufacturing workflow orchestrator known as Maestro. The Maestro submit shares particulars about how the system helps scalability, high-availability, and usefulness, which give the spine for all of our Metaflow initiatives in manufacturing.
A massively necessary element that usually goes ignored is event-triggering: it permits a staff to combine their Metaflow flows to surrounding techniques upstream (e.g. ETL workflows), in addition to downstream (e.g. flows managed by different groups), utilizing a protocol shared by the entire group, as exemplified by the instance use case beneath.
Instance use case: Content material resolution making
Some of the business-critical techniques working on Metaflow helps our content material resolution making, that’s, the query of what content material Netflix ought to carry to the service. We help a large scale of over 260M subscribers spanning over 190 nations representing massively various cultures and tastes, all of whom we wish to delight with our content material slate. Reflecting the breadth and depth of the problem, the techniques and fashions specializing in the query have grown to be very subtle.
We strategy the query from a number of angles however we’ve got a core set of knowledge pipelines and fashions that present a basis for resolution making. As an example the complexity of simply the core parts, take into account this high-level diagram:
On this diagram, grey containers symbolize integrations to associate groups downstream and upstream, inexperienced containers are numerous ETL pipelines, and blue containers are Metaflow flows. These containers encapsulate a whole lot of superior fashions and complicated enterprise logic, dealing with huge quantities of knowledge day by day.
Regardless of its complexity, the system is managed by a comparatively small staff of engineers and information scientists autonomously. That is made attainable by just a few key options of Metaflow:
The staff has additionally developed their very own domain-specific libraries and configuration administration instruments, which assist them enhance and function the system.
To supply enterprise worth, all our Metaflow initiatives are deployed to work with different manufacturing techniques. In lots of instances, the combination could be through shared tables in our information warehouse. In different instances, it’s extra handy to share the outcomes through a low-latency API.
Notably, not all API-based deployments require real-time analysis, which we cowl within the part beneath. We have now numerous business-critical functions the place some or all predictions will be precomputed, guaranteeing the bottom attainable latency and operationally easy excessive availability on the world scale.
We have now developed an formally supported sample to cowl such use instances. Whereas the system depends on our inner caching infrastructure, you might observe the identical sample utilizing companies like Amazon ElasticCache or DynamoDB.
Instance use case: Content material efficiency visualization
The historic efficiency of titles is utilized by resolution makers to grasp and enhance the movie and sequence catalog. Efficiency metrics will be advanced and are sometimes greatest understood by people with visualizations that break down the metrics throughout parameters of curiosity interactively. Content material resolution makers are outfitted with self-serve visualizations via a real-time net utility constructed with metaflow.Cache, which is accessed via an API supplied with metaflow.Internet hosting.
A day by day scheduled Metaflow job computes combination portions of curiosity in parallel. The job writes a big quantity of outcomes to a web-based key-value retailer utilizing metaflow.Cache. A Streamlit app homes the visualization software program and information aggregation logic. Customers can dynamically change parameters of the visualization utility and in real-time a message is distributed to a easy Metaflow internet hosting service which seems to be up values within the cache, performs computation, and returns the outcomes as a JSON blob to the Streamlit utility.
For deployments that require an API and real-time analysis, we offer an built-in mannequin internet hosting service, Metaflow Internet hosting. Though particulars have advanced loads, this outdated speak nonetheless offers a great overview of the service.
Metaflow Internet hosting is particularly geared in direction of internet hosting artifacts or fashions produced in Metaflow. This offers a simple to make use of interface on prime of Netflix’s current microservice infrastructure, permitting information scientists to rapidly transfer their work from experimentation to a manufacturing grade net service that may be consumed over a HTTP REST API with minimal overhead.
Its key advantages embody:
- Easy decorator syntax to create RESTFull endpoints.
- The back-end auto-scales the variety of situations used to again your service primarily based on visitors.
- The back-end will scale-to-zero if no requests are made to it after a specified period of time thereby saving price notably in case your service requires GPUs to successfully produce a response.
- Request logging, alerts, monitoring and tracing hooks to Netflix infrastructure
Think about the service much like managed mannequin internet hosting companies like AWS Sagemaker Mannequin Internet hosting, however tightly built-in with our microservice infrastructure.
Instance use case: Media
We have now an extended historical past of utilizing machine studying to course of media property, as an example, to personalize art work and to assist our creatives create promotional content material effectively. Processing giant quantities of media property is technically non-trivial and computationally costly, so over time, we’ve got developed loads of specialised infrastructure devoted for this objective typically, and infrastructure supporting media ML use instances specifically.
To show the advantages of Metaflow Internet hosting that gives a general-purpose API layer supporting each synchronous and asynchronous queries, take into account this use case involving Amber, our function retailer for media.
Whereas Amber is a function retailer, precomputing and storing all media options prematurely could be infeasible. As an alternative, we compute and cache options in an on-demand foundation, as depicted beneath:
When a service requests a function from Amber, it computes the function dependency graph after which sends a number of asynchronous requests to Metaflow Internet hosting, which locations the requests in a queue, ultimately triggering function computations when compute sources develop into obtainable. Metaflow Internet hosting caches the response, so Amber can fetch it after some time. We may have constructed a devoted microservice only for this use case, however because of the flexibleness of Metaflow Internet hosting, we have been in a position to ship the function sooner with no extra operational burden.
Our urge for food to use ML in various use instances is simply rising, so our Metaflow platform will maintain increasing its footprint correspondingly and proceed to offer pleasant integrations to techniques constructed by different groups at Netlfix. For example, we’ve got plans to work on enhancements within the versioning layer, which wasn’t coated by this text, by giving extra choices for artifact and mannequin administration.
We additionally plan on constructing extra integrations with different techniques which can be being developed by sister groups at Netflix. For example, Metaflow Internet hosting fashions are at the moment not nicely built-in into mannequin logging amenities — we plan on engaged on enhancing this to make fashions developed with Metaflow extra built-in with the suggestions loop vital in coaching new fashions. We hope to do that in a pluggable method that may enable different customers to combine with their very own logging techniques.
Moreover we wish to provide extra methods Metaflow artifacts and fashions will be built-in into non-Metaflow environments and functions, e.g. JVM primarily based edge service, in order that Python-based information scientists can contribute to non-Python engineering techniques simply. This might enable us to raised bridge the hole between the fast iteration that Metaflow offers (in Python) with the necessities and constraints imposed by the infrastructure serving Netflix member going through requests.
If you’re constructing business-critical ML or AI techniques in your group, be part of the Metaflow Slack neighborhood! We’re joyful to share experiences, reply any questions, and welcome you to contribute to Metaflow.
Acknowledgements:
Due to Wenbing Bai, Jan Florjanczyk, Michael Li, Aliki Mavromoustaki, and Sejal Rai for assist with use instances and figures. Due to our OSS contributors for making Metaflow a greater product.







