By Winston Chou, Adrien Alexandre, Lars Olds, Yi Zhang, Garrett Hagemann, and Nathan Kallus

Introduction
Think about asking a knowledge agent to investigate the causal relationship between two variables, such because the impact of watching a well-liked Netflix present on long-term member retention. It queries your knowledge, runs a regression, and confidently returns a solution. How a lot must you belief it? Are you able to be assured that the agent accounted for delicate biases — or does it deal with passionate followers as in the event that they had been the typical viewer? With out deep understanding and experience, would you even be capable of inform if it received the reply mistaken?
Information evaluation is more and more being delegated to software program brokers. Whereas this reduces human effort and toil, oversight continues to be wanted to make sure the validity of outcomes. That is very true for specialised duties like Observational Causal Inference (OCI), which require substantial judgment and area experience.
On this weblog submit, we share an agentic workflow for performing OCI below unconfoundedness. Our workflow is designed for software program brokers to stick to rigorous, exhaustive templates for causal inference duties. But, it additionally seeks to be “human-augmenting,” and to allow and empower human inspection and analysis.
We designed this workflow with OCI practitioners in thoughts. Though OCI requires context and care to do properly, facets of it — e.g., checking and rechecking covariate stability, conducting sensitivity analyses, and maintaining monitor of a number of iterations — might be repetitive and liable to error. Our workflow seeks to remove this toil in order that people can deal with extra nuanced duties, comparable to framing questions, scrutinizing assumptions, and evaluating outcomes.
To this finish, we’re open-sourcing a standalone model of our oci-agent in order that OCI practitioners can mannequin workflows on and counsel enhancements to it. We additionally share evaluations of our agent on the 2016 Atlantic Causal Inference Convention (ACIC) competitors datasets, and present that our agent systematically beats one-shot iterations below quite a few data-generating processes — whereas reaching aggressive outcomes in opposition to hand-tuned benchmarks.
This submit describes the rules behind our workflow and offers a case examine of its deployment at Netflix.
Philosophy
Our workflow is constructed on high of Netflix’s pre-existing OCI toolkit. We constructed this toolkit — largely in a pre-AI world — to reply “point-in-time” causal questions, comparable to “what’s the impact of enjoying a Netflix sport on member retention?” or “what’s the impact of watching a extremely standard present on subsequent engagement?” Questions of this sort inform enterprise technique, information metric growth, and contribute to a wealthy understanding of what drives member satisfaction.
Our toolkit is guided by a “goal trial emulation” philosophy. For any point-in-time OCI query, we ask “what’s the splendid A/B take a look at for addressing this query?” This A/B take a look at could also be costly, sluggish, and even infeasible to run. Nonetheless, the thought train helps to pin down the assumptions wanted for a reputable reply, comparable to unconfoundedness of the remedy.
To make the goal trial analogy actionable, our toolkit embeds a sequence of design diagnostics. These diagnostics assess whether or not we’re drawing truthful comparisons between handled and untreated items — or if there are hidden variations that might imperil our conclusions:
- Covariate stability. After weighting, the standardized imply distinction of pre-treatment covariates between remedy and management teams must be lower than 0.2.
- Overlap. The chance of receiving remedy (aka propensity rating) must be bounded between 0.1 and 0.9.
- Placebo end result. The “remedy impact” on variables measured previous to the remedy shouldn’t be considerably completely different from zero.
- Sensitivity to hidden confounders. Findings of remedy results are contextualized by sensitivity to hypothetical omitted variables that specify each remedy and end result.
As we uplevel our OCI toolkit with brokers, such analysis stays paramount. The usual method to evaluating brokers is to programmatically examine their outputs to floor fact. But, exterior of artificially simulated knowledge, there is no such thing as a floor fact in observational causal inference.
With out discounting the necessity for evals (which our workflow additionally helps), one among our key rules is to reinforce human analysis by making every analytic step as clear as attainable. For instance, in our workflow, brokers publish artifacts within the type of plans, specs, plots, and notebooks that people can examine and re-execute if they want. Within the absence of floor fact, we depend on these “course of audits” — coupled with human oversight — to construct good brokers.
Rules
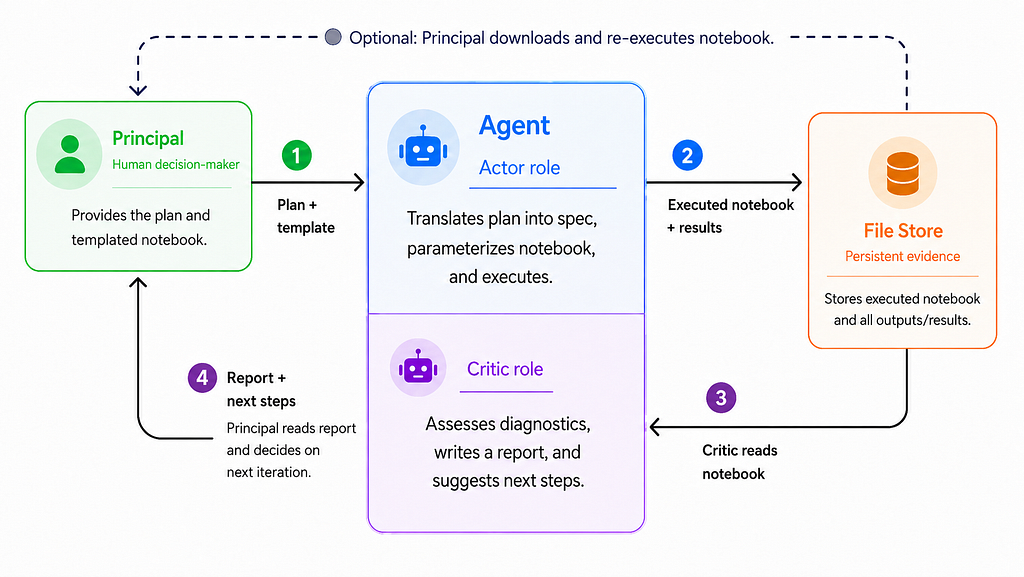
Our workflow has three key personas:
- Principal — the human consumer (e.g., knowledge scientist) whose purpose is to offer an intensive and proper evaluation
- Actor — the software program persona that performs the evaluation, together with diagnostics
- Critic — the software program persona that synthesizes outcomes, identifies gaps, and presents strategies to enhance the evaluation
Our agent orchestrates the latter two personas in an actor-critic loop: specifying and triggering the evaluation because the actor, then decoding outcomes and diagnosing flaws because the critic.
Every persona has duties:
Principals
- Present an preliminary evaluation plan containing its context and targets.
- Present context on the primary threats to legitimate inference and the confounders that should be managed.
- Specify the instruments that can be utilized for the evaluation.
- Specify the information mannequin and dataset.
Actors
- Refine the principal’s plan into a knowledge evaluation spec.
- Use solely the instruments supplied by the principal.
- Create human- and machine-checkable artifacts.
- Carry out the 4 design diagnostics along with the core evaluation.
- Report any remediations taken in case of diagnostic failures.
Critics
- Verify for blind spots, comparable to unmentioned confounders, within the principal’s plan.
- Verify for alignment between the plan, spec, and executed evaluation.
- Specify a credibility degree within the outcomes after seeing the diagnostics.
- Specify if and the way the estimand differs from the Common Remedy Impact (ATE), for instance resulting from propensity rating trimming.
- Distinction the executed evaluation with the best goal Randomized Managed Trial (RCT).
- Recommend at the very least one various measurement technique (e.g., encouragement RCTs).
Though our workflow is designed for OCI below unconfoundedness, the rules listed on this part are supposed to be extensible to different approaches to OCI, comparable to panel strategies with very completely different assumptions (e.g., parallel tendencies).
Empowering Human Analysis
To empower human oversight of every analytic step, we offer principals with a templated pocket book that makes use of our vetted (non-agentic) OCI toolkit, which employs doubly sturdy studying for causal impact estimation.
The principal’s remaining duties are to jot down the preliminary evaluation plan and to guage the evaluation artifacts (the executed pocket book and the critic’s report). To allow thorough analysis, brokers version-control their experiences and add executed notebooks to a file retailer, the place they are often downloaded and re-executed by principals (in the event that they want).
We diagram this workflow under:
Case Research — Estimating the Impression of New Leisure Sorts
In recent times, now we have added all kinds of leisure sorts past streaming video to Netflix. A pure query is how these new leisure sorts have an effect on members’ satisfaction and their probability of continuous to subscribe to Netflix.
To investigate the impression of one among these new leisure sorts, which we are going to name Kind X, we wrote a easy evaluation plan specifying our
- Remedy: Days participating with Kind X (or “Kind X days” for quick)
- End result: Two-month retention
- Potential confounders, together with pre-treatment Kind X days
To determine a baseline, we fed this evaluation plan with out extra scaffolding to Claude Sonnet 4.6, a strong but accessible general-purpose mannequin. The mannequin selected and executed a defensible evaluation technique: linearly regressing retention on Kind X days together with controls.
Whereas the consequence was polished and spectacular, once we ran the identical evaluation by way of our paved path tooling and agentic workflow, additionally utilizing Sonnet 4.6, our agent produced an up to date estimate that was simply 25% of the baseline! What explains the distinction between the baseline and the paved-path estimates?
A core problem when analyzing new leisure sorts is early adopter bias. The primary customers of any new providing are more likely to be systematically completely different from the final inhabitants. For instance, they might be heavier customers of Netflix usually, or they might be extraordinarily robust followers of the underlying titles. Early adopter bias manifested in our evaluation as poor “overlap”: the overwhelming majority of observations had a small estimated chance of participating with Kind X, reflecting its early maturity.
This imbalance was caught by our critic agent in its writeup of the evaluation. The critic additionally flagged the failure of the placebo take a look at: early Kind X adopters differed considerably from non-adopters by way of essential confounders measured earlier than experiencing the remedy, a warning signal of potential bias.
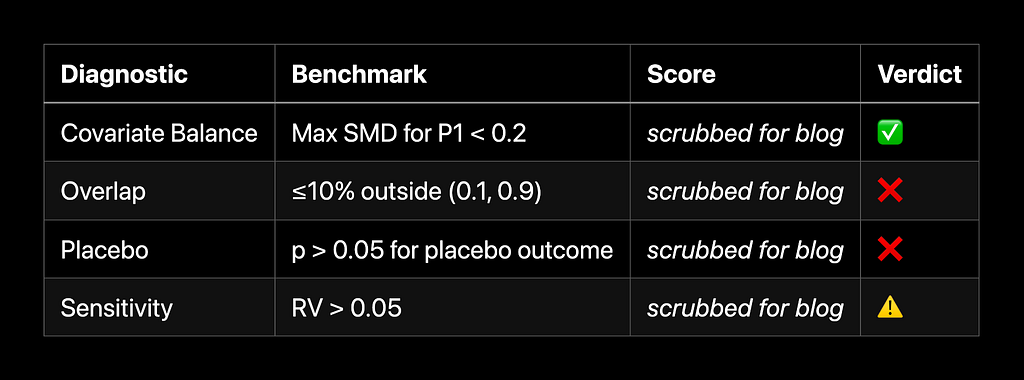
Addressing Failed Diagnostics
To handle these diagnostic failures, our workflow supplies brokers with a playbook. For instance, to beat poor overlap, we instruct the agent to make use of Crump-style trimming. That’s, earlier than estimating causal results, the actor trims items with estimated propensity scores exterior the vary [0.1, 0.9]. This scopes the remedy impact being estimated to the ATE within the inhabitants that’s not very probably or unlikely to have interaction within the new leisure sort — an essential caveat we instruct the critic to flag in its report.
Trimming yields an estimate that’s a lot smaller than the baseline estimate, and which solely applies to the “overlapping” inhabitants (for whom engagement with the brand new leisure sort is non-deterministic). Nonetheless, the trimmed estimate is considerably extra credible, because it focuses on the members for whom the remedy might plausibly be randomly assigned, as in a goal trial.
Contrastively, the baseline impact depends closely on assumptions to extrapolate outcomes for all members, even these with a really low chance of remedy. The hazard right here is that extrapolation produces a quantity that’s not backed by sturdy knowledge and is probably going confounded by early adopter bias.
Orchestrating Followup Analyses
There are two pure followups to this evaluation:
- First, we have to analyze the sensitivity of estimates to the selection of trimming threshold. Virtually, this requires redoing the evaluation with a number of trimming thresholds.
- Second, we additionally care about how these causal results evolve over time. But, evaluating causal results throughout time raises delicate challenges. For instance, we have to coordinate the inhabitants throughout all analyses: if a set of customers is trimmed to make one evaluation extra credible, it must be trimmed within the different analyses as properly.
Each of those followups require conducting a number of variations of the identical evaluation, tweaking some parameters whereas maintaining others the identical. Managing this complexity and guaranteeing constant execution is one other space the place brokers add worth.
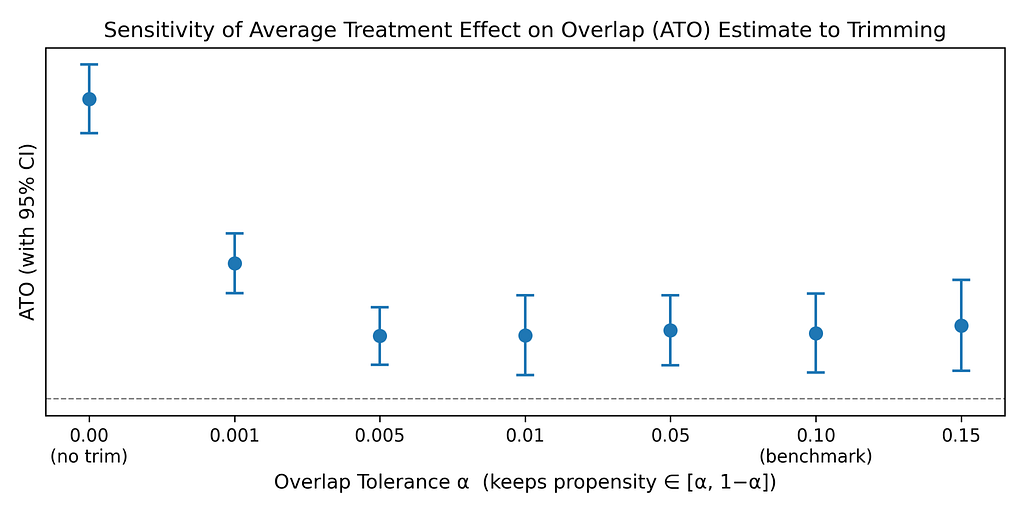
For example this, under we present a sensitivity evaluation for our case examine wherein we requested the agent to fluctuate the trimming bounds from [0, 1] (no trimming) to [0.15, 0.85]. Because the plot reveals, the estimated ATE on the overlapping inhabitants is strong to the selection of trimming threshold inside bounds of [0.005, 0.995]. Though principals might (and may) execute this and different robustness analyses, delegating them to brokers helps to scale back toil.
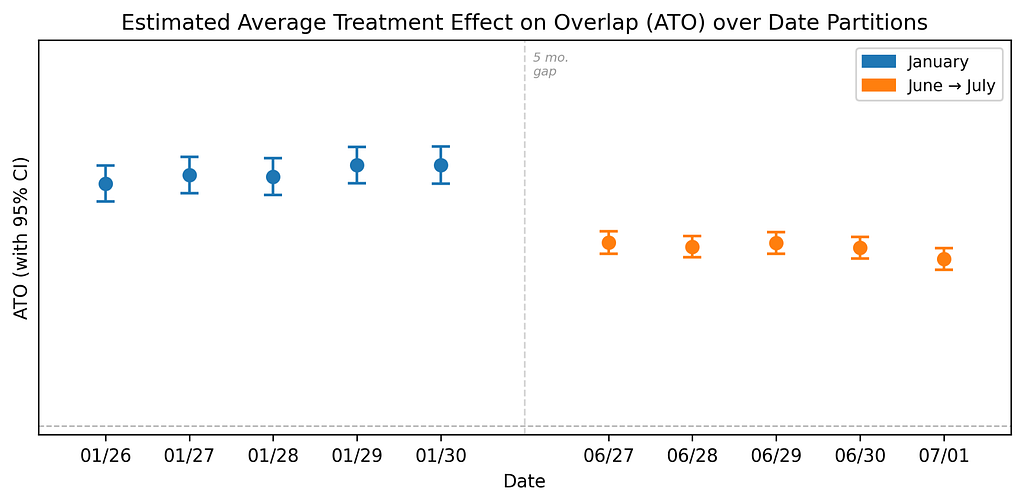
One other instance is producing a time sequence by repeating the identical evaluation throughout a number of date partitions. For instance, under we plot the outcomes of utilizing our agent to refit a distinct evaluation on ten distinct date partitions. The plot reveals proof of seasonality: the remedy has a stronger impact on the winter dates in comparison with the summer time dates.
Public Repo and Evals
To assist OCI practitioners construct on and contribute to our workflow, we’re open-sourcing a standalone model of oci-agent. This repo implements two evaluations on public datasets from the 2016 Atlantic Causal Inference Competitors (ACIC) knowledge evaluation competitors. It additionally features a light-weight model of our inside causal machine studying pocket book that solely makes use of open-source software program (EconML).
Our first analysis runs this pocket book for 3 randomly sampled datasets generated by every of the 77 data-generating processes (DGPs) within the ACIC knowledge. Subsequent, it makes use of the critic to grade the ensuing 231 estimates as both passable or unsatisfactory primarily based on the diagnostics.
Beneath, we plot the typical RMSE and protection of 95% confidence intervals of our ATT estimates in opposition to the 44 competitor strategies within the ACIC competitors. Because the scatterplot reveals, our statistical methodology is aggressive in opposition to these benchmarks: it achieves moderately low RMSE and well-calibrated confidence intervals that cowl the reality in ~95% of DGPs.
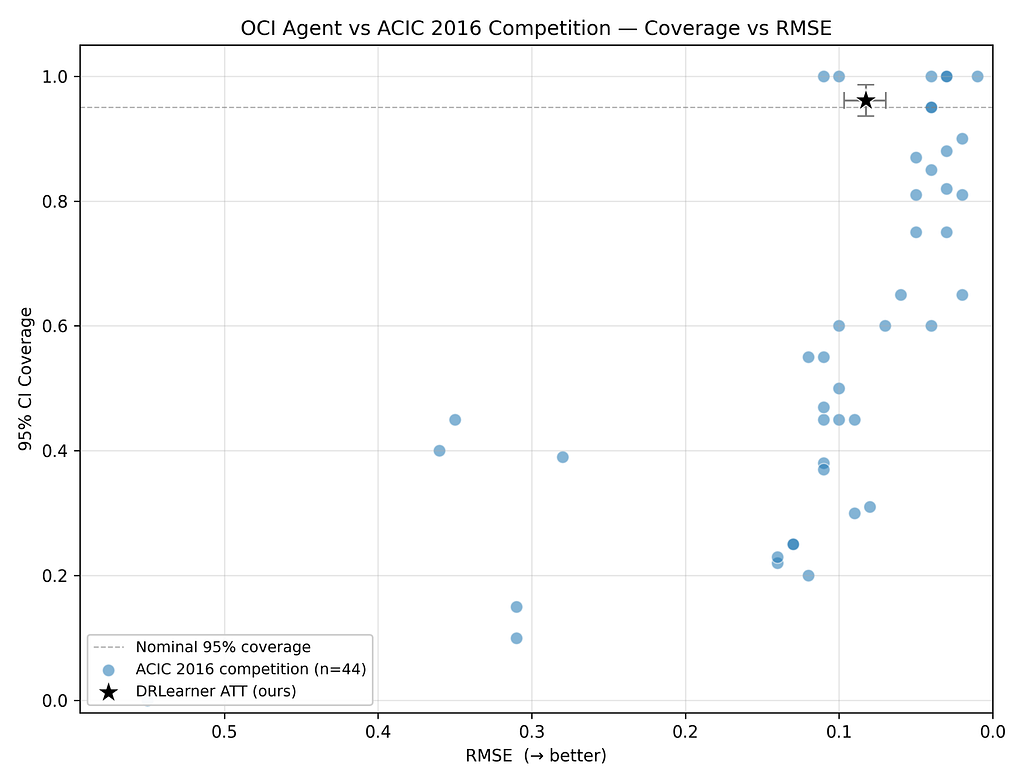
Extra to the purpose, our diagnostics and agentic workflow assist to separate extra dependable estimates from much less dependable estimates. For example this, the next chart plots our ATE estimates by way of RMSE and protection. Observe that we separate out the RMSE and protection of:
- All 231 estimates (purple dot)
- The 192 passable estimates (blue star)
- The 39 unsatisfactory estimates (crimson dot)
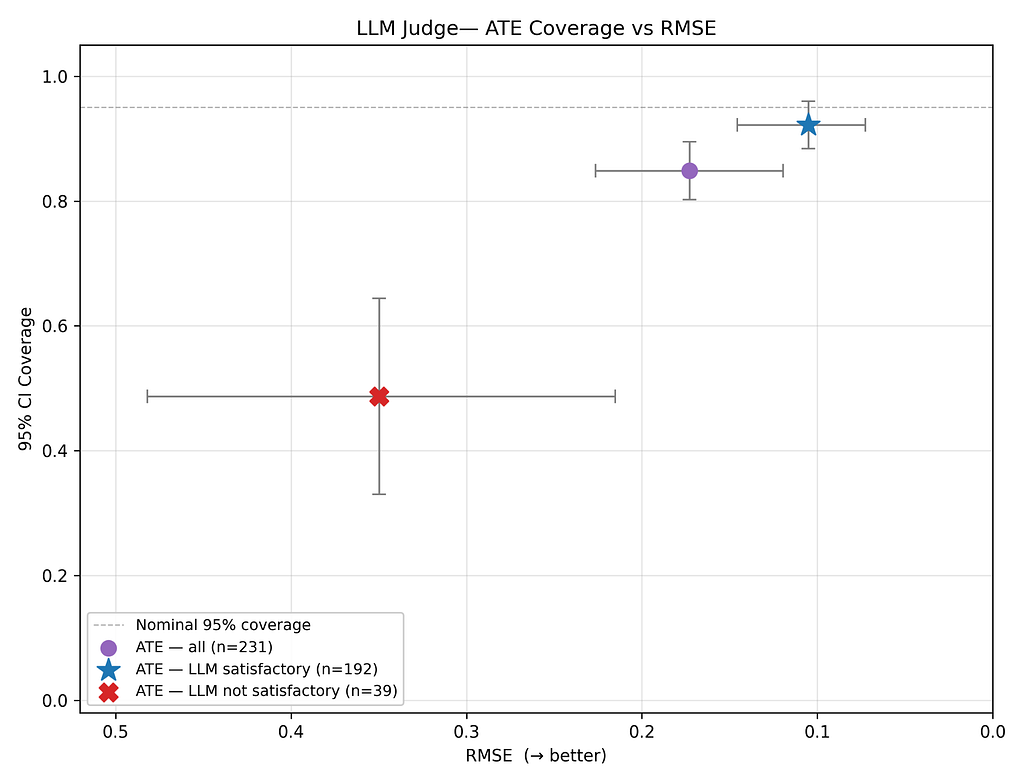
Because the plot reveals, when aided by our diagnostic suite, the critic agent is ready to separate good estimates from unhealthy estimates: the passable estimates have a lot decrease RMSE and higher calibrated confidence intervals than do the unsatisfactory estimates.
Our second analysis compares the efficiency of an LLM on the identical evaluation plan with our scaffolding and with out it (i.e., one-shot prompting). Unsurprisingly, we discover that our scaffolding is vital to serving to the LLM return helpful estimates. This may be seen within the following random pattern of ten ACIC datasets. Utilizing our scaffolding, the LLM recovers the bottom fact in 9 out of ten datasets. Moreover, estimates are extremely correlated with floor fact.
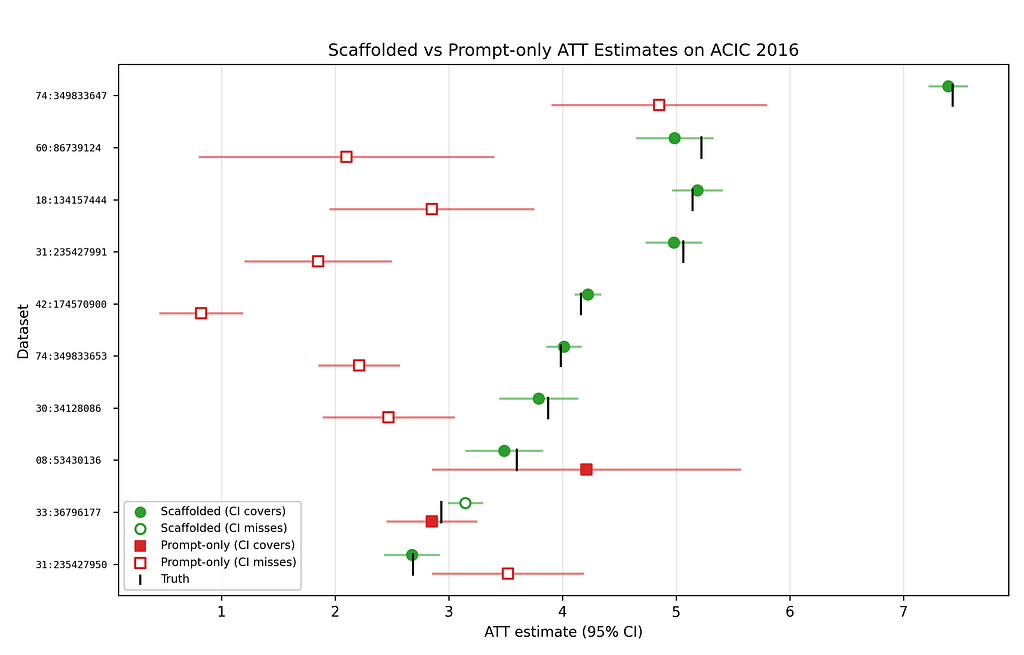
In distinction, giving the identical evaluation plan to Sonnet 4.6 with none scaffolding (i.e., simply prompting it) ends in constantly mistaken solutions that aren’t in any respect correlated with floor fact.
A key limitation of our public repo is that, because of the artificial nature of the underlying datasets, it doesn’t pressure-test our agent’s semantic understanding or efficiency on real-world OCI duties. Nonetheless, the repo demonstrates the core rules underlying our workflow. These embrace (1) giving brokers with in depth scaffolding in order that they observe finest practices by design, and (2) requiring inspectable artifacts in order that people can audit brokers’ processes, not simply their outcomes.
Conclusion
We offer a workflow for doing observational causal inference with the assistance of software program brokers. Leveraging components of our pre-AI OCI toolkit, comparable to templated notebooks, our workflow is designed to make sure that brokers conduct rigorous and exhaustive analyses. This helps to scale back the human toil of OCI, which could be a extremely iterative and exacting course of.
On the similar time, motivated by the complexity and ambiguity of observational causal inference, our workflow seeks to be human-augmenting and permits human practitioners to guage every analytic step.
Utilizing brokers for causal inference poses a problem: how will we consider brokers’ efficiency on duties with out floor fact? To fulfill this problem, our workflow combines course of audits with human oversight. To allow others to study from and critique our workflow, now we have open-sourced a light-weight, standalone model. We hope this work stimulates extra analysis and growth on agentic analysis within the absence of floor fact.
For helpful suggestions on this submit and “dogfooding,” we thank Adith Swaminathan, Ayal Chen-Zion, Colin Grey, Juliet Hougland, and Simon Ejdemyr.
![]()
A Human-Augmenting Agentic Workflow for Causal Inference was initially printed in Netflix TechBlog on Medium, the place individuals are persevering with the dialog by highlighting and responding to this story.