By Christos G. Bampis, Zhi Li, Kyle Swanson, Nil Fons Miret and Pavan Madhusudanarao
Will this encode look good to Netflix members? Does switching to a brand new codec enhance high quality on the similar bitrate and by how a lot? What’s the easiest way to encode a film title given a goal bitrate finances? For years, VMAF has reliably helped us reply these questions and ship an optimized high quality of expertise to our members.
However good isn’t ok. If VMAF misjudges high quality, that will result in lack of element for a suspenseful close-up or banding for a surprising wide-angle sky shot. That’s lots of belief to place in a single quantity, so we attempt to verify it earns it. Over time, we collected suggestions from VMAF customers, each internally and externally. Just a few years in the past, we launched into a journey to develop a brand new model of VMAF to handle a few of its recognized limitations. Right now, we’re pleased to announce that we’re open-sourcing a brand new model of VMAF, with model quantity v1. Through the use of VMAF v1 we will extra precisely assess visible high quality and therefore effectively ship increased high quality for Netflix members worldwide. On this publish we share how v1 addresses the earlier model’s (known as VMAF v0) limitations and among the challenges we confronted alongside the approach.
What’s VMAF and why enhance it?
VMAF (Video Multimethod Evaluation Fusion) is a video high quality metric that Netflix developed with college companions and open-sourced on GitHub. It has turn into a de facto customary for encoding analysis and optimization for the video business. VMAF combines elementary quality-aware options and fuses them with a support-vector regressor (SVR) skilled on subjective knowledge. For background, see our first, second and third VMAF tech blogs.
Regardless of its accuracy and extensive adoption, we now have recognized room to enhance the core of the algorithm. That’s central to our mission of delivering the very best visible high quality to our members regardless of the place and the way they watch Netflix. As new codecs, like AV2, are developed and use circumstances like reside streaming and cloud gaming emerge, we attempt to proceed to enhance VMAF to serve these enterprise wants. We describe every key enchancment beneath.
Bettering sensitivity to compression artifacts
As mentioned in our first VMAF tech weblog [1], a typical encoding pipeline introduces each compression and scaling artifacts. Intuitively, when extra bits can be found, increased resolutions are preferable. VMAF quantifies the tradeoff between compression and scaling and determines the optimum decision to make use of given a bitrate finances. This may be demonstrated by a VMAF vs. bitrate curve.

In apply, we noticed that VMAF v0 tends to favor switching to the next decision at decrease bitrates, preferring compression artifacts over scaling, which could possibly be visually annoying. This may be partially attributed to the DLM (Element Loss Metric) function, which penalizes distinction/element loss, however could also be much less delicate to distracting artifacts, like blockiness [3]. In VMAF v1, to enrich DLM, we added the AIM (additive impairments) part [3] from the unique ADM formulation with minor modifications to enhance accuracy. These two elementary metrics are linearly mixed, just like the unique implementation in [3].
One VMAF mannequin to rule them all
A primary-order impact that influences high quality notion is the visibility of artifacts and its relationship to viewing distance and canvas measurement. Put merely, the identical encoded video seems to be higher when displayed on a smaller canvas or considered from additional away.

The usual VMAF mannequin assumes that viewers sit in entrance of a 1920×1080 show, in a residing room-like surroundings, with a normalized viewing distance of roughly 3× the display screen top (3H). Because of this the usual 1080p@3H VMAF mannequin corresponds to a viewing angle of roughly 60 pixels per diploma.
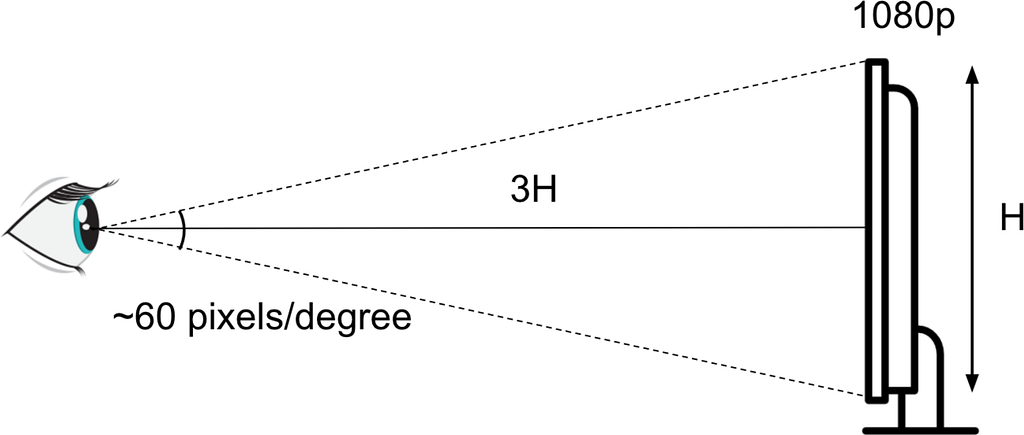
For telephone viewing, given a smaller display screen measurement and longer pure viewing distance (typical telephone viewing could be approximated as 4 to 5H) relative to the display screen top, we anticipate that artifacts turn into much less seen. The telephone mannequin of VMAF v0 captures this by post-processing the usual (TV/laptop computer) VMAF rating by a second-order polynomial mapping. This mapping was estimated utilizing subjective knowledge.
One downside of the above mapping is that it’s exhausting to generalize predictions for the myriad of viewing situations that materially differ from the unique subjective experiment. Additional, in apply, we noticed that the telephone mannequin can overpredict high quality. In v1, as a substitute of utilizing a mapping perform, we regulate the elementary function values based mostly on the normalized viewing distance. The identical mannequin can then be skilled and reapplied for various use circumstances, e.g., telephone viewing, 4K@3H, or a extra discerning 4K@1.5H. We discovered that this method improves accuracy and helps generalize VMAF higher.
To attain this, we modulate the spatial distinction sensitivity perform (CSF) utilized in DLM based mostly on the normalized viewing distance. The CSF defines human sensitivity to distinction throughout spatial frequencies and is expounded to distortion perceptibility. The CSF can therefore be used to estimate perceived distortion for various viewing distances, show sizes, and resolutions. An instance CSF curve is proven beneath.
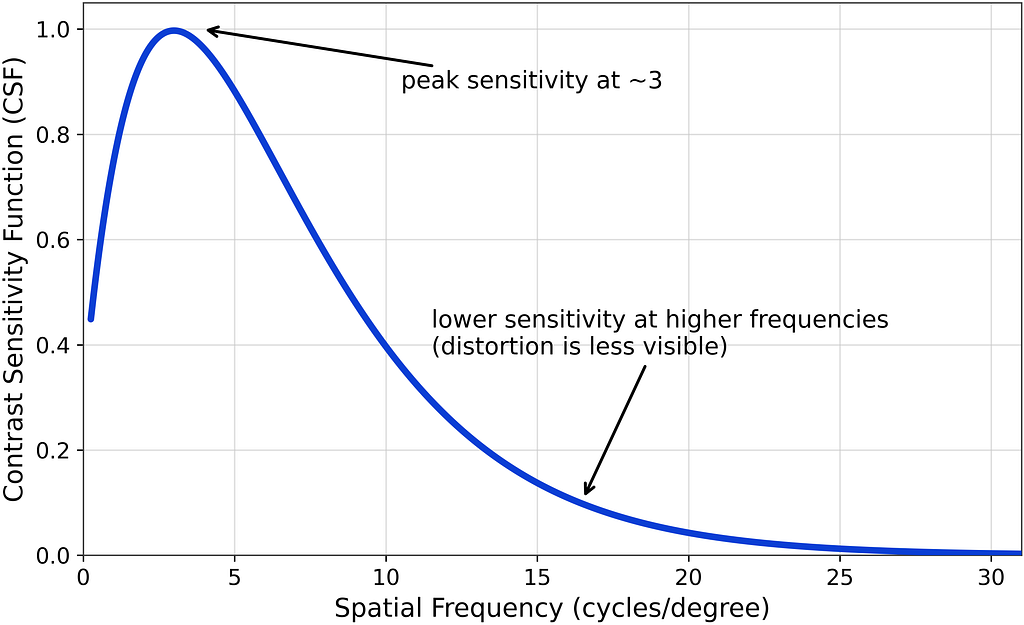
Because the viewing distance will increase, extra pixels match into a level of visible angle, which lowers distortion visibility. In VMAF v1, we use an tailored model of Barten’s CSF mannequin from [4].
Addressing banding artifacts
Banding exhibits up as staircase-like edges in components of the picture that ought to look clean. It will probably have a adverse visible impression for viewers, however this impression isn’t captured nicely by VMAF v0. VMAF v1 integrates the Distinction Conscious Multiscale Banding Index (CAMBI) as one of many elementary options. You may learn extra about CAMBI in our earlier tech weblog or the technical paper.
Addressing chroma artifacts
VMAF v0 solely extracts luma-based options, so it’s unaware of chroma artifacts. In apply, encoding and scaling introduce chroma artifacts by way of quantization and subsampling. To seize such artifacts, we modified SpEED-QA and utilized it to the chroma channels.
Leveraging the no-enhancement acquire (NEG) mode
To scale back the impact of picture enhancement operations, like sharpening, a standalone no-enhancement acquire (NEG) mode was made out there for VMAF v0. Now we have discovered that NEG serves as a conservative high quality metric and helps protect inventive intent. We already use VMAF-NEG as one of many high quality metrics throughout codec improvement, corresponding to for AV2. Due to this fact, NEG is enabled by default for VMAF v1 with no want for a separate mannequin.
Bettering the movement function
VMAF v0’s movement function doesn’t have an higher sure. Additional, the coaching knowledge used then didn’t have sufficient protection for high-motion sequences. Consequently, we noticed that VMAF v0 may overpredict high quality for very high-motion scenes. On the flip facet, since movement differencing in v0 was carried out between consecutive frames, v0 would underpredict high quality for sequences with body charges increased than 24 or 30 fps, like 60 fps. In v1, we apply an empirically derived exhausting threshold to the movement function. Additional, we add an choice to measure movement variations over a bigger temporal window. Increasing the temporal window alone doesn’t absolutely seize the perceptual impression of 60 fps, nevertheless it does scale back the underprediction evident in v0.
Overview of VMAF v1 fashions
VMAF v1 helps the next fashions:
- Customary 1080p Mannequin: This mannequin is calibrated for 1080p video considered at a typical 3H distance. It makes use of an working vary of [0, 100].
- Telephone Mannequin: Derived by setting the normalized viewing distance to 5H (based mostly on experimental knowledge), this mannequin adjusts the DLM, AIM, and chroma function calculations to mirror diminished artifact visibility on smaller screens considered from a larger relative distance. It retains the usual [0, 100] vary.
- 4K Mannequin: We launch two v1 4K fashions: a 1.5H variant and a 3H variant. The 1.5H variant is predicated on a discerning 4K@1.5H viewing situation. This variant is conceptually just like its v0 4K counterpart and operates on a [0, 100] vary. For many customers, this variant is the default selection. The 3H variant is predicated on a consumer-like 4K@3H viewing situation. This variant operates on a [0, 110] vary, which helps to quantify the extra perceptual good thing about 4K decision over 1080p when each are considered at 3H.
Decoding the rating
VMAF v1’s rating and interpretation are largely per v0’s. To attain this, we calibrated the VMAF v1 scale to align with v0 by way of a rating remodel, in order that the brand new algorithm preserves the that means of the numbers whereas protecting its accuracy advantages.
Placing v1 to the check
We consider VMAF v1 throughout a number of subjective datasets. These datasets cowl a wide range of codecs, content material varieties, and use circumstances. For simplicity, we report the Spearman’s rank correlation coefficient (SRCC) for VMAF v0 and v1. SRCC values nearer to 1 present increased settlement with subjective knowledge. Full outcomes will probably be out there in a future technical paper.
Within the desk beneath, if a dataset is marked as “4K” then we measure VMAF at 4K utilizing the 4K@1.5H mannequin, in any other case we measure VMAF at 1080p, utilizing the suitable 1080p mannequin. If a dataset is marked as “telephone” the 1080p telephone mannequin is used, in any other case the usual 1080p@3H mannequin is used.
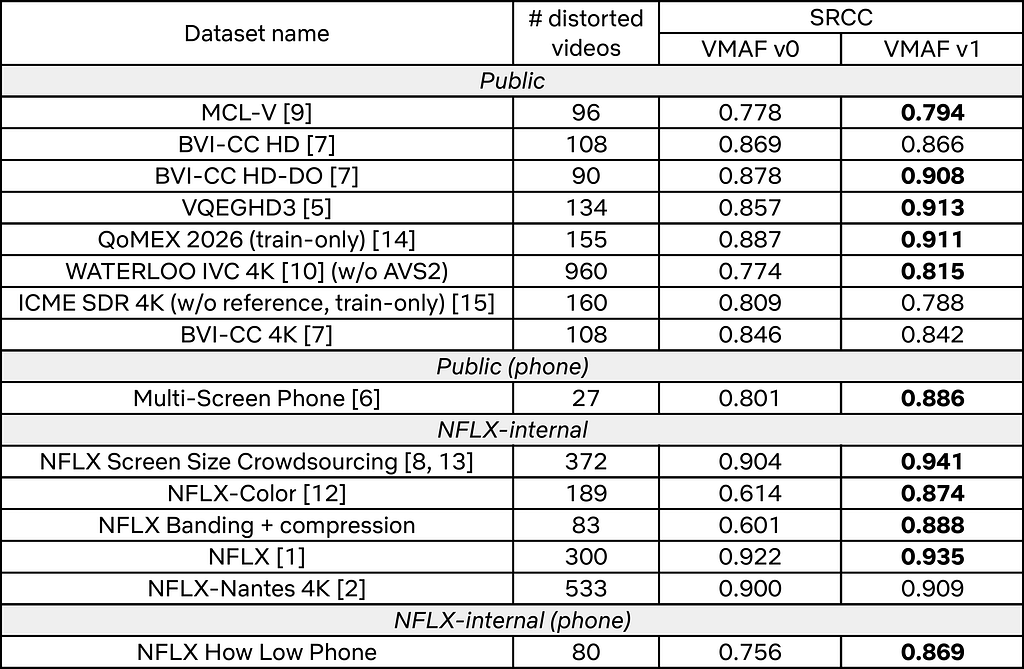
As seen above, VMAF v1 matches or outperforms v0 in most datasets. There are notable enhancements on giant datasets like WATERLOO IVC 4K and the Netflix Display screen Dimension Crowdsourcing, on datasets with chroma and banding artifacts, and those who contain telephone viewing. On just a few datasets we observe minor regressions, that are small relative to the positive aspects elsewhere.
Working v1
Even with the addition of latest options, we needed VMAF v1 to have a diminished computational complexity when put next with VMAF v0. To attain this, we have:
- Eliminated VIF (Visible Data Constancy) as a core VMAF function. VIF is computationally complicated and didn’t meaningfully enhance accuracy after updating the opposite options.
- Launched just a few CAMBI-specific optimizations, each algorithmic and software program.
- Measured the chroma function at a decrease scale, which doesn’t damage accuracy [11].
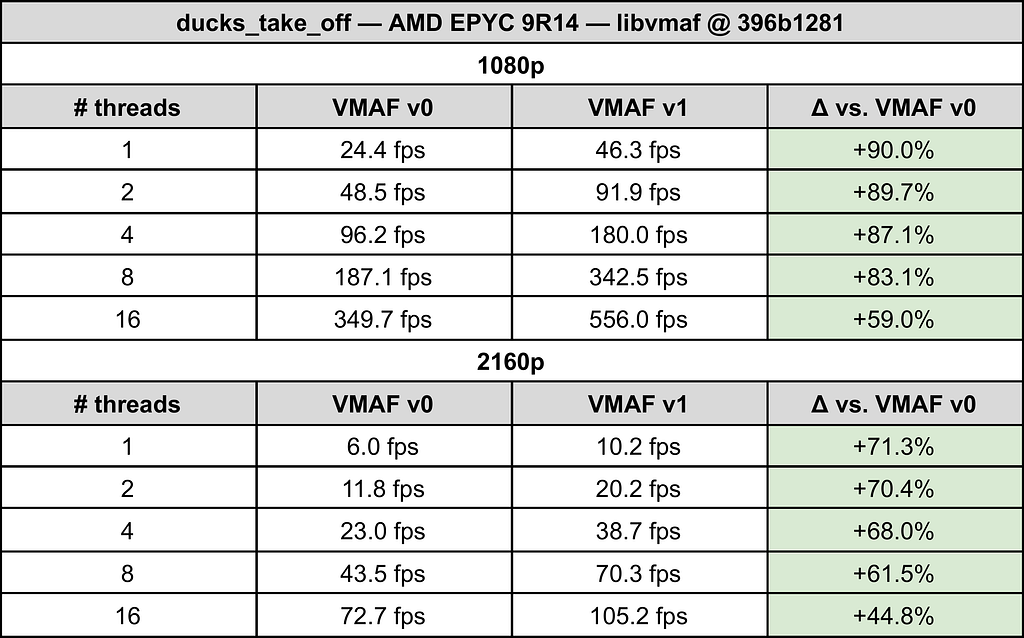
The results of this work isn’t solely a extra correct VMAF, but additionally a a lot quicker VMAF. The desk beneath exhibits the processing velocity and threading efficiency for every VMAF mannequin at 1080p and 4K. Moreover, our latest libvmaf launch has a a lot improved threading efficiency, which is of profit to each v0 and v1. Notice that for content material with important banding, computing CAMBI provides some overhead, which may scale back this speedup.
Holding some outdated (and good) habits
Whereas the core of the algorithm has modified, we nonetheless suggest:
- Computing VMAF on the proper decision by upsampling the distorted video to the supply decision, in order that each compression and scaling artifacts are mirrored. For instance, bicubic upsampling can be utilized as a basic approximation.
- Decoding scores in context by utilizing the correct mannequin (e.g. 1080p vs. 4K vs. telephone) on your state of affairs by bearing in mind viewing distance assumptions.
This isn’t the tip of the highway
Identical to any metric, VMAF v1 isn’t excellent. There’s nonetheless room for enchancment. Some areas that we’re engaged on addressing sooner or later are: film-grain noise, improved dealing with for prime body charges, and perceptual codec optimizations corresponding to adaptive quantization. We invite the neighborhood to attempt the newest VMAF fashions, report edge circumstances, contribute to the open-source code, and assist enhance VMAF. We plan to publish an in depth technical paper for VMAF v1. We additionally plan to launch an HDR model enhanced by the v1 enhancements, so keep tuned!
Acknowledgments
This was a collaborative effort propelled by our beautiful colleagues. We wish to thank the next people: Xiaoqing Zhu, Mariana Afonso, Anush Moorthy, Raymond Walsh, Omair Akhtar, Amelia Taylor, Ken Thomas, Zheng Lu, Chris Pham, Alex Chang, Prudhvi Chaganti, Ben Wallen, Craig Howland, Deepthi Arun, Andy Rhines and Lukáš Krasula.
References
[1] Z. Li et al., “Towards a sensible perceptual video high quality metric,” Netflix Know-how Weblog, 2016.
[2] Z. Li et al., “VMAF: The journey continues,” Netflix Know-how Weblog, 2018.
[3] S. Li, F. Zhang, L. Ma, and Ok. Ngan, “Picture High quality Evaluation by Individually Evaluating Element Losses and Additive Impairments,” IEEE Transactions on Multimedia, 2011.
[4] P. G. J. Barten, Distinction Sensitivity of the Human Eye and Its Results on Picture High quality. SPIE Press, 1999.
[5] Video High quality Consultants Group, “Report on the validation of video high quality fashions for prime definition video content material,” 2010.
[6] N. Barman, Y. Reznik, and M. G. Martini, “A Subjective Dataset for Multi-Display screen Video Streaming Functions,” Worldwide Convention on High quality of Multimedia Expertise (QoMEX), Ghent, Belgium, 2023, pp. 270–275.
[7] A. Katsenou, F. Zhang, M. Afonso, G. Dimitrov, and D. R. Bull, “BVI-CC: A Dataset for Analysis on Video Compression and High quality Evaluation,” Frontiers in Sign Processing, vol. 2, 2022.
[8] C. G. Bampis, L. Krasula, Z. Li, and O. Akhtar, “Measuring and Predicting Perceptions of Video High quality Throughout Display screen Sizes with Crowdsourcing,” Worldwide Convention on High quality of Multimedia Expertise (QoMEX), Ghent, Belgium, 2023, pp. 13–18.
[9] J. Y. Lin, R. Music, C.-H. Wu, T. J. Liu, H. Wang, and C.-C. J. Kuo, “MCL-V: A streaming video high quality evaluation database,” Journal of Visible Communication and Picture Illustration, vol. 30, pp. 1–9, Jul. 2015.
[10] Z. Li, Z. Duanmu, W. Liu, and Z. Wang, “AVC, HEVC, VP9, AVS2 or AV1? — A Comparative Examine of State-of-the-Artwork Video Encoders on 4K Movies,” Int. Conf. Picture Evaluation and Recognition (ICIAR), 2019.
[11] C. G. Bampis, P. Gupta, R. Soundararajan, and A. C. Bovik, “SpEED-QA: Spatial Environment friendly Entropic Differencing for Picture and Video High quality,” IEEE Sign Course of. Lett., vol. 24, no. 9, pp. 1333–1337, Sep. 2017.
[12] L.-H. Chen, C. G. Bampis, Z. Li, J. Sole, and A. C. Bovik, “Perceptual video high quality prediction emphasizing chroma distortions,” IEEE Trans. Picture Course of., vol. 30, pp. 1941–1954, 2021.
[13] C. G. Bampis et al., “NFLX Display screen Dimension Crowdsourcing dataset,” 2023.
[14] H. Wei, P. Lebreton, Y. Chen, J. Zhu, and P. Le Callet, “Grand Problem on Video High quality Evaluation for Uneven Encoded Movies,” Int. Conf. High quality of Multimedia Expertise (QoMEX), Cardiff, U.Ok., 2026.
[15] Y. Chen, B. Chen, H. Wei, A. C. Bovik et al., “ICME 2025 Generalizable HDR and SDR Video High quality Measurement Grand Problem,” arXiv:2506.22790, 2025.
![]()
VMAF v1: Good Is Not Good Sufficient was initially printed in Netflix TechBlog on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.