











By Meenakshi Jindal
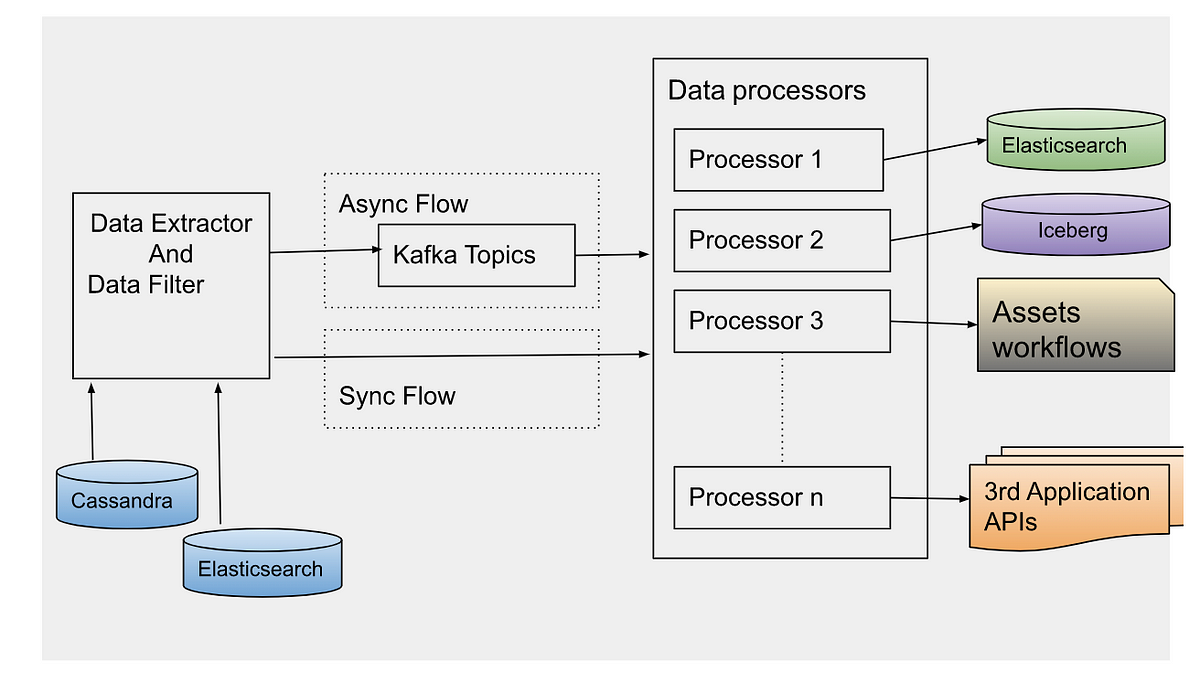
At Netflix, we constructed the asset administration platform (AMP) as a centralized service to arrange, retailer and uncover the digital media property created through the film manufacturing. Studio purposes use this service to retailer their media property, which then goes by way of an asset cycle of schema validation, versioning, entry management, sharing, triggering configured workflows like inspection, proxy technology and so on. This platform has developed from supporting studio purposes to knowledge science purposes, machine-learning purposes to find the property metadata, and construct varied knowledge info.
Throughout this evolution, very often we obtain requests to replace the prevailing property metadata or add new metadata for the brand new options added. This sample grows over time when we have to entry and replace the prevailing property metadata. Therefore we constructed the information pipeline that can be utilized to extract the prevailing property metadata and course of it particularly to every new use case. This framework allowed us to evolve and adapt the applying to any unpredictable inevitable modifications requested by our platform purchasers with none downtime. Manufacturing property operations are carried out in parallel with older knowledge reprocessing with none service downtime. A number of the widespread supported knowledge reprocessing use instances are listed under.
- Actual-Time APIs (backed by the Cassandra database) for asset metadata entry don’t match analytics use instances by knowledge science or machine studying groups. We construct the information pipeline to persist the property knowledge within the iceberg in parallel with cassandra and elasticsearch DB. However to construct the information info, we want the entire knowledge set within the iceberg and never simply the brand new. Therefore the prevailing property knowledge was learn and copied to the iceberg tables with none manufacturing downtime.
- Asset versioning scheme is developed to help the most important and minor model of property metadata and relations replace. This characteristic help required a major replace within the knowledge desk design (which incorporates new tables and updating present desk columns). Current knowledge bought up to date to be backward suitable with out impacting the prevailing working manufacturing site visitors.
- Elasticsearch model improve which incorporates backward incompatible modifications, so all of the property knowledge is learn from the first supply of fact and reindexed once more within the new indices.
- Information Sharding technique in elasticsearch is up to date to offer low search latency (as described in weblog put up)
- Design of latest Cassandra reverse indices to help completely different units of queries.
- Automated workflows are configured for media property (like inspection) and these workflows are required to be triggered for previous present property too.
- Property Schema bought developed that required reindexing all property knowledge once more in ElasticSearch to help search/stats queries on new fields.
- Bulk deletion of property associated to titles for which license is expired.
- Updating or Including metadata to present property due to some regressions in consumer utility/inside service itself.
Cassandra is the first knowledge retailer of the asset administration service. With SQL datastore, it was straightforward to entry the prevailing knowledge with pagination whatever the knowledge measurement. However there isn’t a such idea of pagination with No-SQL datastores like Cassandra. Some options are supplied by Cassandra (with newer variations) to help pagination like pagingstate, COPY, however every one among them has some limitations. To keep away from dependency on knowledge retailer limitations, we designed our knowledge tables such that the information could be learn with pagination in a performant approach.
Primarily we learn the property knowledge both by asset schema varieties or time bucket based mostly on asset creation time. Information sharding fully based mostly on the asset sort might have created the extensive rows contemplating some varieties like VIDEO might have many extra property in comparison with others like TEXT. Therefore, we used the asset varieties and time buckets based mostly on asset creation date for knowledge sharding throughout the Cassandra nodes. Following is the instance of tables major and clustering keys outlined:
Primarily based on the asset sort, first time buckets are fetched which is determined by the creation time of property. Then utilizing the time buckets and asset varieties, an inventory of property ids in these buckets are fetched. Asset Id is outlined as a cassandra Timeuuid knowledge sort. We use Timeuuids for AssetId as a result of it may be sorted after which used to help pagination. Any sortable Id can be utilized because the desk major key to help the pagination. Primarily based on the web page measurement e.g. N, first N rows are fetched from the desk. Subsequent web page is fetched from the desk with restrict N and asset id < final asset id fetched.
Information layers could be designed based mostly on completely different enterprise particular entities which can be utilized to learn the information by these buckets. However the major id of the desk needs to be sortable to help the pagination.
Generally we’ve got to reprocess a particular set of property solely based mostly on some area within the payload. We are able to use Cassandra to learn property based mostly on time or an asset sort after which additional filter from these property which fulfill the person’s standards. As an alternative we use Elasticsearch to go looking these property that are extra performant.
After studying the asset ids utilizing one of many methods, an occasion is created per asset id to be processed synchronously or asynchronously based mostly on the use case. For asynchronous processing, occasions are despatched to Apache Kafka matters to be processed.
Information processor is designed to course of the information in a different way based mostly on the use case. Therefore, completely different processors are outlined which could be prolonged based mostly on the evolving necessities. Information could be processed synchronously or asynchronously.
Synchronous Stream: Relying on the occasion sort, the particular processor could be instantly invoked on the filtered knowledge. Usually, this stream is used for small datasets.
Asynchronous Stream: Information processor consumes the information occasions despatched by the information extractor. Apache Kafka matter is configured as a message dealer. Relying on the use case, we’ve got to regulate the variety of occasions processed in a time unit e.g. to reindex all the information in elasticsearch due to template change, it’s most well-liked to re-index the information at sure RPS to keep away from any influence on the working manufacturing workflow. Async processing has the profit to regulate the stream of occasion processing with Kafka shoppers depend or with controlling thread pool measurement on every shopper. Occasion processing may also be stopped at any time by disabling the shoppers in case manufacturing stream will get any influence with this parallel knowledge processing. For quick processing of the occasions, we use completely different settings of Kafka shopper and Java executor thread pool. We ballot data in bulk from Kafka matters, and course of them asynchronously with a number of threads. Relying on the processor sort, occasions could be processed at excessive scale with proper settings of shopper ballot measurement and thread pool.
Every of those use instances talked about above appears completely different, however all of them want the identical reprocessing stream to extract the previous knowledge to be processed. Many purposes design knowledge pipelines for the processing of the brand new knowledge; however organising such an information processing pipeline for the prevailing knowledge helps dealing with the brand new options by simply implementing a brand new processor. This pipeline could be thoughtfully triggered anytime with the information filters and knowledge processor sort (which defines the precise motion to be carried out).
Errors are a part of software program growth. However with this framework, it needs to be designed extra rigorously as bulk knowledge reprocessing shall be executed in parallel with the manufacturing site visitors. Now we have arrange the completely different clusters of knowledge extractor and processor from the primary Manufacturing cluster to course of the older property knowledge to keep away from any influence of the property operations dwell in manufacturing. Such clusters might have completely different configurations of thread swimming pools to learn and write knowledge from database, logging ranges and connection configuration with exterior dependencies.
Information processors are designed to proceed processing the occasions even in case of some errors for eg. There are some surprising payloads in previous knowledge. In case of any error within the processing of an occasion, Kafka shoppers acknowledge that occasion is processed and ship these occasions to a special queue after some retries. In any other case Kafka shoppers will proceed making an attempt to course of the identical message once more and block the processing of different occasions within the matter. We reprocess knowledge within the useless letter queue after fixing the basis explanation for the problem. We accumulate the failure metrics to be checked and stuck later. Now we have arrange the alerts and repeatedly monitor the manufacturing site visitors which could be impacted due to the majority previous knowledge reprocessing. In case any influence is observed, we must always be capable of decelerate or cease the information reprocessing at any time. With completely different knowledge processor clusters, this may be simply executed by lowering the variety of situations processing the occasions or lowering the cluster to 0 situations in case we want an entire halt.
- Relying on present knowledge measurement and use case, processing might influence the manufacturing stream. So determine the optimum occasion processing limits and accordingly configure the patron threads.
- If the information processor is looking any exterior providers, examine the processing limits of these providers as a result of bulk knowledge processing might create surprising site visitors to these providers and trigger scalability/availability points.
- Backend processing might take time from seconds to minutes. Replace the Kafka shopper timeout settings accordingly in any other case completely different shopper might attempt to course of the identical occasion once more after processing timeout.
- Confirm the information processor module with a small knowledge set first, earlier than set off processing of the entire knowledge set.
- Acquire the success and error processing metrics as a result of generally previous knowledge might have some edge instances not dealt with accurately within the processors. We’re utilizing the Netflix Atlas framework to gather and monitor such metrics.
Burak Bacioglu and different members of the Asset Administration platform staff have contributed within the design and growth of this knowledge reprocessing pipeline.







