











By Burak Bacioglu, Meenakshi Jindal
At Netflix, all of our digital media belongings (photos, movies, textual content, and so on.) are saved in safe storage layers. We constructed an asset administration platform (AMP), codenamed Amsterdam, in an effort to simply arrange and handle the metadata, schema, relations and permissions of those belongings. Additionally it is liable for asset discovery, validation, sharing, and for triggering workflows.
Amsterdam service makes use of numerous options equivalent to Cassandra, Kafka, Zookeeper, EvCache and so on. On this weblog, we will likely be specializing in how we make the most of Elasticsearch for indexing and search the belongings.
Amsterdam is constructed on prime of three storage layers.
The primary layer, Cassandra, is the supply of reality for us. It consists of near 100 tables (column households) , the vast majority of that are reverse indices to assist question the belongings in a extra optimized approach.
The second layer is Elasticsearch, which is used to find belongings based mostly on person queries. That is the layer we’d wish to give attention to on this weblog. And extra particularly, how we index and question over 7TB of knowledge in a read-heavy and repeatedly rising setting and hold our Elasticsearch cluster wholesome.
And eventually, we’ve got an Apache Iceberg layer which shops belongings in a denormalized vogue to assist reply heavy queries for analytics use instances.
Elasticsearch is likely one of the finest and broadly adopted distributed, open supply search and analytics engines for every type of knowledge, together with textual, numerical, geospatial, structured or unstructured knowledge. It supplies easy APIs for creating indices, indexing or looking paperwork, which makes it straightforward to combine. Irrespective of whether or not you utilize in-house deployments or hosted options, you may rapidly get up an Elasticsearch cluster, and begin integrating it out of your utility utilizing one of many shoppers offered based mostly in your programming language (Elasticsearch has a wealthy set of languages it helps; Java, Python, .Web, Ruby, Perl and so on.).
One of many first selections when integrating with Elasticsearch is designing the indices, their settings and mappings. Settings embrace index particular properties like variety of shards, analyzers, and so on. Mapping is used to outline how paperwork and their fields are purported to be saved and listed. You outline the information sorts for every subject, or use dynamic mapping for unknown fields. You could find extra info on settings and mappings on Elasticsearch web site.
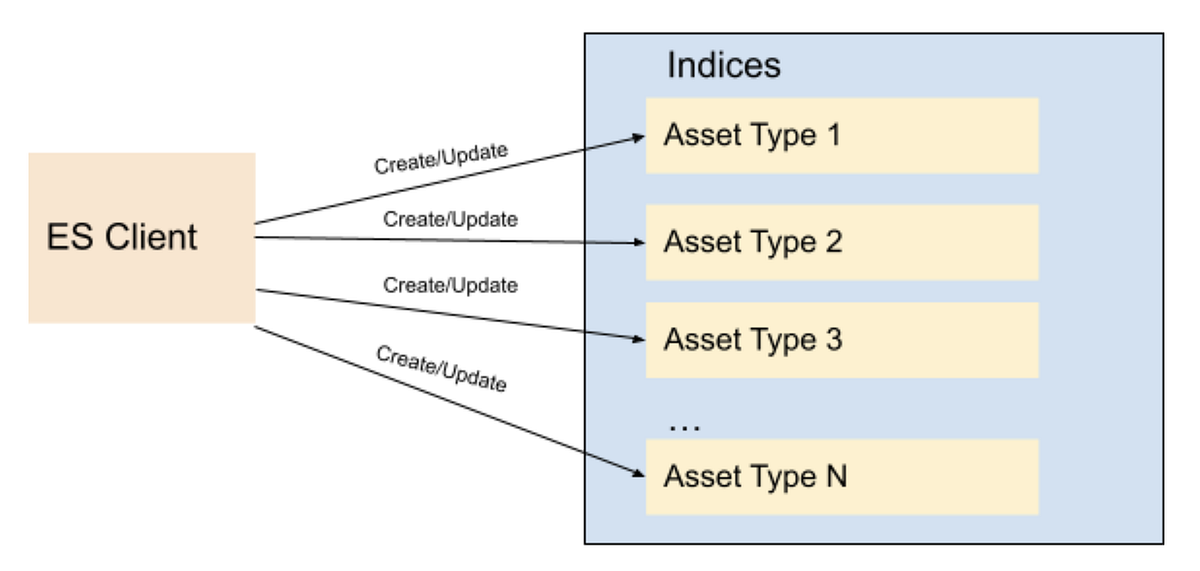
Most functions in content material and studio engineering at Netflix take care of belongings; equivalent to movies, photos, textual content, and so on. These functions are constructed on a microservices structure, and the Asset Administration Platform supplies asset administration to these dozens of companies for numerous asset sorts. Every asset kind is outlined in a centralized schema registry service liable for storing asset kind taxonomies and relationships. Subsequently, it initially appeared pure to create a distinct index for every asset kind. When creating index mappings in Elasticsearch, one has to outline the information kind for every subject. Since totally different asset sorts might doubtlessly have fields with the identical identify however with totally different knowledge sorts; having a separate index for every kind would forestall such kind collisions. Subsequently we created round a dozen indices per asset kind with fields mapping based mostly on the asset kind schema. As we onboarded new functions to our platform, we stored creating new indices for the brand new asset sorts. We have now a schema administration microservice which is used to retailer the taxonomy of every asset kind; and this programmatically created new indices every time new asset sorts have been created on this service. All of the belongings of a particular kind use the precise index outlined for that asset kind to create or replace the asset doc.
As Netflix is now producing considerably extra originals than it used to after we began this mission a couple of years in the past, not solely did the variety of belongings develop dramatically but additionally the variety of asset sorts grew from dozens to a number of 1000’s. Therefore the variety of Elasticsearch indices (per asset kind) in addition to asset doc indexing or looking RPS (requests per second) grew over time. Though this indexing technique labored easily for some time, attention-grabbing challenges began arising and we began to note efficiency points over time. We began to look at CPU spikes, lengthy working queries, cases going yellow/purple in standing.
Normally the very first thing to strive is to scale up the Elasticsearch cluster horizontally by growing the variety of nodes or vertically by upgrading occasion sorts. We tried each, and in lots of instances it helps, however typically it’s a brief time period repair and the efficiency issues come again after some time; and it did for us. You understand it’s time to dig deeper to grasp the foundation reason behind it.
It was time to take a step again and reevaluate our ES knowledge indexing and sharding technique. Every index was assigned a set variety of 6 shards and a couple of replicas (outlined within the template of the index). With the rise within the variety of asset sorts, we ended up having roughly 900 indices (thus 16200 shards). A few of these indices had thousands and thousands of paperwork, whereas a lot of them have been very small with solely 1000’s of paperwork. We discovered the foundation reason behind the CPU spike was unbalanced shards dimension. Elasticsearch nodes storing these giant shards grew to become scorching spots and queries hitting these cases have been timing out or very gradual as a consequence of busy threads.
We modified our indexing technique and determined to create indices based mostly on time buckets, fairly than asset sorts. What this implies is, belongings created between t1 and t2 would go to the T1 bucket, belongings created between t2 and t3 would go to the T2 bucket, and so forth. So as a substitute of persisting belongings based mostly on their asset sorts, we’d use their ids (thus its creation time; as a result of the asset id is a time based mostly uuid generated on the asset creation) to find out which period bucket the doc needs to be persevered to. Elasticsearch recommends every shard to be underneath 65GB (AWS recommends them to be underneath 50GB), so we might create time based mostly indices the place every index holds someplace between 16–20GB of knowledge, giving some buffer for knowledge progress. Current belongings could be redistributed appropriately to those precreated shards, and new belongings would at all times go to the present index. As soon as the scale of the present index exceeds a sure threshold (16GB), we’d create a brand new index for the following bucket (minute/hour/day) and begin indexing belongings to the brand new index created. We created an index template in Elasticsearch in order that the brand new indices at all times use the identical settings and mappings saved within the template.
We selected to index all variations of an asset within the the identical bucket – the one which retains the primary model. Subsequently, although new belongings can by no means be persevered to an outdated index (as a consequence of our time based mostly id technology logic, they at all times go to the newest/present index); current belongings could be up to date, inflicting extra paperwork for these new asset variations to be created in these older indices. Subsequently we selected a decrease threshold for the roll over in order that older shards would nonetheless be properly underneath 50GB even after these updates.
For looking functions, we’ve got a single learn alias that factors to all indices created. When performing a question, we at all times execute it on the alias. This ensures that regardless of the place paperwork are, all paperwork matching the question will likely be returned. For indexing/updating paperwork, although, we can’t use an alias, we use the precise index identify to carry out index operations.
To keep away from the ES question for the record of indices for each indexing request, we hold the record of indices in a distributed cache. We refresh this cache every time a brand new index is created for the following time bucket, in order that new belongings will likely be listed appropriately. For each asset indexing request, we have a look at the cache to find out the corresponding time bucket index for the asset. The cache shops all time-based indices in a sorted order (for simplicity we named our indices based mostly on their beginning time within the format yyyyMMddHHmmss) in order that we are able to simply decide precisely which index needs to be used for asset indexing based mostly on the asset creation time. With out utilizing the time bucket technique, the identical asset might have been listed into a number of indices as a result of Elasticsearch doc id is exclusive per index and never the cluster. Or we must carry out two API calls, first to establish the precise index after which to carry out the asset replace/delete operation on that particular index.
It’s nonetheless attainable to exceed 50GB in these older indices if thousands and thousands of updates happen inside that point bucket index. To handle this difficulty, we added an API that will break up an outdated index into two programmatically. With the intention to break up a given bucket T1 (which shops all belongings between t1 and t2) into two, we select a time t1.5 between t1 and t2, create a brand new bucket T1_5, and reindex all belongings created between t1.5 and t2 from T1 into this new bucket. Whereas the reindexing is going on, queries / reads are nonetheless answered by T1, so any new doc created (through asset updates) could be dual-written into T1 and T1.5, offered that their timestamp falls between t1.5 and t2. Lastly, as soon as the reindexing is full, we allow reads from T1_5, cease the twin write and delete reindexed paperwork from T1.
In reality, Elasticsearch supplies an index rollover function to deal with the rising indicex downside https://www.elastic.co/information/en/elasticsearch/reference/6.0/indices-rollover-index.html. With this function, a brand new index is created when the present index dimension hits a threshold, and thru a write alias, the index calls will level to the brand new index created. Meaning, all future index calls would go to the brand new index created. Nonetheless, this could create an issue for our replace move use case, as a result of we must question a number of indices to find out which index accommodates a selected doc in order that we are able to replace it appropriately. As a result of the calls to Elasticsearch might not be sequential, which means, an asset a1 created at T1 could be listed after one other asset a2 created at T2 the place T2>T1, the older asset a1 can find yourself within the newer index whereas the newer asset a2 is persevered within the outdated index. In our present implementation, nevertheless, by merely trying on the asset id (and asset creation time), we are able to simply discover out which index to go to and it’s at all times deterministic.
One factor to say is, Elasticsearch has a default restrict of 1000 fields per index. If we index every type to a single index, wouldn’t we simply exceed this quantity? And what concerning the knowledge kind collisions we talked about above? Having a single index for all knowledge sorts might doubtlessly trigger collisions when two asset sorts outline totally different knowledge sorts for a similar subject. We additionally modified our mapping technique to beat these points. As a substitute of making a separate Elasticsearch subject for every metadata subject outlined in an asset kind, we created a single nested kind with a compulsory subject known as `key`, which represents the identify of the sector on the asset kind, and a handful of data-type particular fields, equivalent to: `string_value`, `long_value`, `date_value`, and so on. We’d populate the corresponding data-type particular subject based mostly on the precise knowledge kind of the worth. Under you may see part of the index mapping outlined in our template, and an instance from a doc (asset) which has 4 metadata fields:
As you see above, all asset properties go underneath the identical nested subject `metadata` with a compulsory `key` subject, and the corresponding data-type particular subject. This ensures that regardless of what number of asset sorts or properties are listed, we’d at all times have a set variety of fields outlined within the mapping. When trying to find these fields, as a substitute of querying for a single worth (cameraId == 42323243), we carry out a nested question the place we question for each key and the worth (key == cameraId AND long_value == 42323243). For extra info on nested queries, please discuss with this hyperlink.
After these adjustments, the indices we created are actually balanced when it comes to knowledge dimension. CPU utilization is down from a mean of 70% to 10%. As well as, we’re in a position to cut back the refresh interval time on these indices from our earlier setting 30 seconds to 1 sec in an effort to assist use instances like learn after write, which allows customers to look and get a doc after a second it was created
We needed to do a one time migration of the prevailing paperwork to the brand new indices. Fortunately we have already got a framework in place that may question all belongings from Cassandra and index them in Elasticsearch. Since doing full desk scans in Cassandra will not be typically beneficial on giant tables (as a consequence of potential timeouts), our cassandra schema accommodates a number of reverse indices that assist us question all knowledge effectively. We additionally make the most of Kafka to course of these belongings asynchronously with out impacting our actual time visitors. This infrastructure is used not solely to index belongings to Elasticsearch, but additionally to carry out administrative operations on all or some belongings, equivalent to bulk updating belongings, scanning / fixing issues on them, and so on. Since we solely centered on Elasticsearch indexing on this weblog, we’re planning to create one other weblog to speak about this infrastructure later.







